在增强现实(AR)与自动驾驶的时代来临之际,3D数据呈现爆炸式增长。在不久的将来,处理3D数据的算法将应用于像机器人自动巡航、基于AR的智能用户界面等应用程序上。受此启发,我们在Matroid公司所著的论文提出了FusionNet,这一框架用于在一个名为Princeton ModelNet的标准数据集上做3D CAD物体分类。
FusionNet的核心是全新的、应用于3D物体的三维卷积神经网络(Convolutional Neural Networks, CNN)。我们必须在多个方面调整传统的CNN以使其有效。为了解释得清楚些,我们不妨先看一下用于图像分类的二维CNN。这个思路是,机器学习研究者会构建数个隐层形成的模型,每一层与前一层都以不同的形式连接。在第一层,你会拥有一个在二维图像上滑动的一块窗口区域作为输入。因为这个区域执行了卷积操作——在窗口滑动时它交叠其上,因此它被称为卷积层。其后还有几层不同形式的隐层,最后一层用于预测潜在的输出;每一种输出对应着图像标注中的某种分类。在ModelNet40 Challenge数据集中,存在40个分类,因此模型中最后一层有40个神经元。第一类可能是『猫』,第二类可能是『车辆』,以此类推遍历数据集包含的所有分类。如果第一个神经元在40个中激发的最厉害,那么输入样本就会被判别为第一类,一只猫。
整个模型假设输入是图片形式,即二维数据。你该如何将它拓展到三维呢?一种可能的方法是,就像显示器显示三维物体那样,先把物体通过投影处理成二维图像,然后在其上运行标准的二维CNN算法。实际上,现在在Princeton ModelNet Challenge数据集上已提交的最优算法的思路是,把任何3D物体在多个角度上对物体进行一组2D投影进行『像素表达』,然后使用卷积神经网络。FusionNet确实也基于像素表达使用了CNN,但关键是,它同时还增加了一种新式的三维CNN。
与在二维图像上滑动一个区域不同的是,我们可以在物体上滑动一块三维空间了!在这种表达之下,没有必要做投影这一步。这种方法用『体积表达』来处理物体。
在我们的体积表达中,3D物体被离散化为30*30*30的体素(译者注:volumepixel,文中简称voxel)网格。如果物体的任何部分位于1*1*1的体素中,就给体素赋值为1,反之则赋值为0. 与之前的工作不同的是,我们在学习物体特征的过程中同时用到了像素表达和体素表达,这种方法对分类3D CAD物体而言,比单独使用其中一种要好。其中一些例子如下:

图 1. 两种表达. 左图:浴缸、高脚凳、坐便器与衣橱的2D投影。右图:体素化之后的浴缸、高脚凳、坐便器与衣橱. 感谢Reza Zadeh提供图片
我们建立了两种处理体素数据的卷积神经网络(V-CNN I与V-CNN II),以及一种处理像素数据的网络(MV-CNN). 下图显示了这些网络是如何结合在一起工作,并给出对于物体分类的最终判断的。处理2D图像的标准CNN就不一样了,它们只能从图像中学到一些空间局部特征。
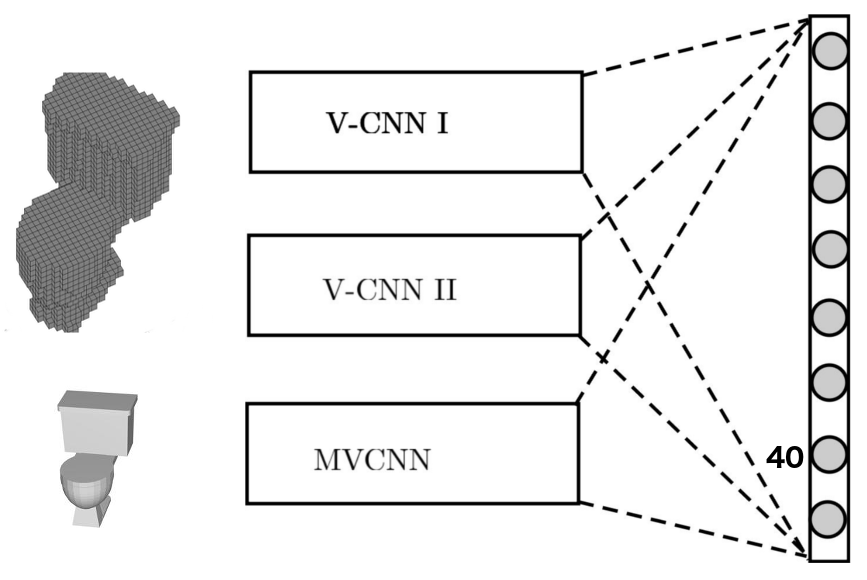
图2. FusionNet是三种神经网络的混合,它们分别是V-CNN I, V-CNN II, and MV-CNN (最后一种神经网络是基于AlexNet结构构建的,并经过ImageNet数据集预训练过 ) 这三种网络在评分层进行了融合,通过计算打分的线性组合找到最终所预测的分类。前两个网络使用了体素化的CAD模型,最后一种网络则使用2D投影作为输入。感谢Reza Zadeh提供图片
我们使用了标准预训练神经网络模型(AlexNet)作为2D网络MV-CNN的基础,对3D物体2D投影的网络进行暖启动(warm-start)预训练基于大规模2D像素图片数据集ImageNet。受预训练影响,许多用于2D图像分类的特征不需要从头开始训练了。下图所描绘的框架是我们使用的V-CNN之一种(V-CNN I):
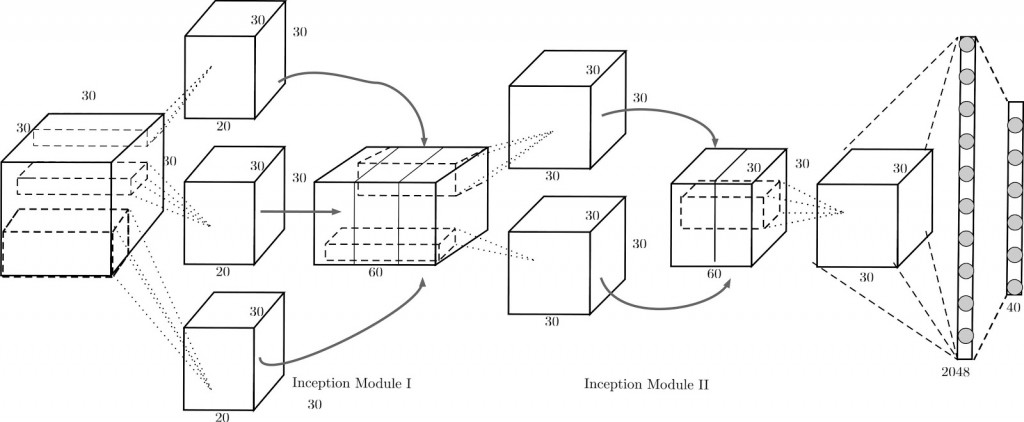
图 3. 感谢Reza Zadeh提供图片
V-CNN I所使用的框架受到GoogLeNet(www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf)启发, 使用了Inception模块。Inception模块对不同大小的核处理结果进行了拼接,它有助于神经网络学习不同尺度的特征,并在紧接着Inception模块的下一层卷积层中共享参数。
概括来说,FusionNet是三种神经网络的融合,其中一种基于像素表达,两种基于物体的体素化表达。它利用了每一种网络的强项,提高了分类器性能。FusionNet中的每一个网络组分都在对物体分类之前以多个角度、方向观察物体。尽管从直觉来说,对物体的多角度观察确实能比单角度观察带来更多信息,但是将信息整合到一起以提高预测精度并不显而易见。我们使用了20个像素表达特征与60个CAD物体体素表达特征这么多信息用于进行物体分类。FusionNet的效果超越了在Princeton ModelNet 40类数据集榜单上排名第一的提交方案,展示了其独到的能力。
相关链接:
•参考在2016年8月2日大规模机器学习会议(scaledml.org)Reza Zadeh的发言
•『Strata+Hadoop World』2016纽约活动中的深度学习议题

Reza Zadeh
Reza Zadeh是斯坦福大学的一名顾问教授,同时也是拟阵(Matroid)公司的创始人,CEO。他的工作集中在机器学习,分布式计算,以及离散数学方面。他同时供职于微软以及DataBricks的技术咨询委员会。





