深入强化学习可能是一个难以掌握的领域。 在人们试图学习如何解决强化学习问题时,很难在海量的缩略词和机器学习模型间找到一个最好的着力点。强化学习理论并非新鲜事物,事实上,一部分强化学习的理论可以追溯到20世纪50年代中期。 如果你是强化学习领域彻头彻尾的新手,我建议你查阅我以前的文章『关于强化学习和OpenAI Gym的介绍』,学习强化学习的基础知识。
深度强化学习需要更新大量的梯度,深度学习工具(如TensorFlow)对于计算这些梯度非常有用。 深度强化学习也要求抽象地表示视觉状态,在这种情况下,卷积神经网络效果最好。 在本文中我们将使用Python,TensorFlow和强化学习库Gym来解决3D 游戏Doom中的医疗包收集问题。 要获取完整的代码和所需的依赖库,请访问本文的GitHub仓库和Jupyter Notebook 。
探索环境
在这种环境下,Doom玩家站在酸性液体上,为了保持存活,需要学习如何搜寻并收集医疗包。
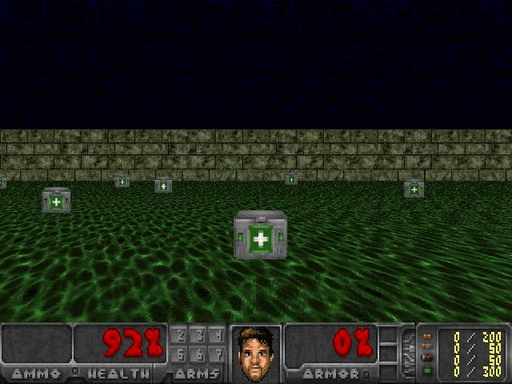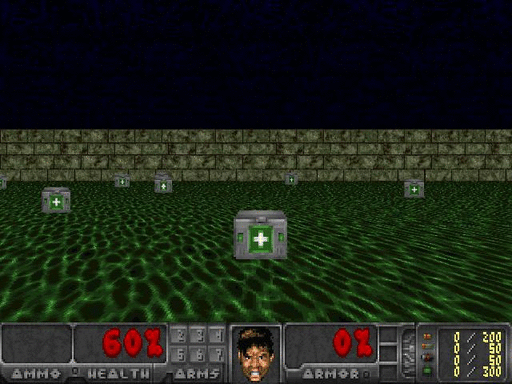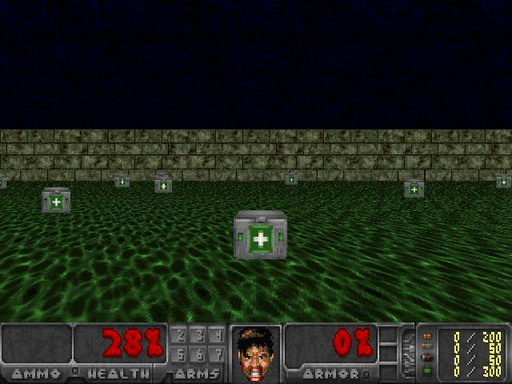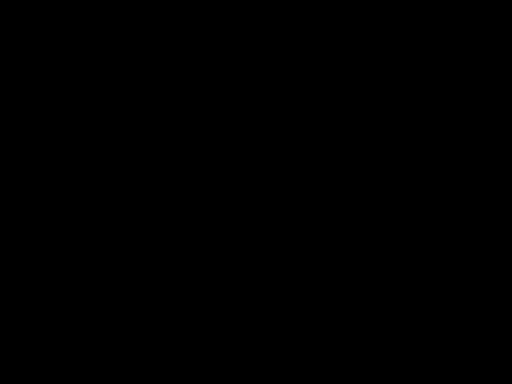
图1.训练环境,感谢Justin Francis提供图片
为了解决这一问题,强化学习算法的选择之一是使用REINFORCE作为基线算法。 Reinforce是非常简单的 —— 在环境的一个周期中,它需要的数据仅包括两种:状态,以及奖励。 Reinforce 被称为策略梯度法(Policy Gradient Method),因为它只是评估和更新智能体的策略。 策略(Policy)就是在当前状态下,智能体的行为方式。 例如,在一个名为『Pong』的弹球游戏中,一个简单的策略是:如果球沿着某个角度移动,最好的动作就是将球拍移动到相对该角度的同一侧位置。 在使用卷积神经网络来估计任何给定状态(state)下的最佳策略之前,我们会使用同一个网络来估计给定状态下的价值(value)或预期的长期收益(reward)。
我们会通过使用Gym库来定义我们的环境。
env = gym . make ( ‘ppaquette/DoomHealthGathering-v0’ )
在试图让智能体进行学习之前,让我们通过观察随机游走智能体,看一下基线标准。 很明显,我们有很多东西要『学习』。
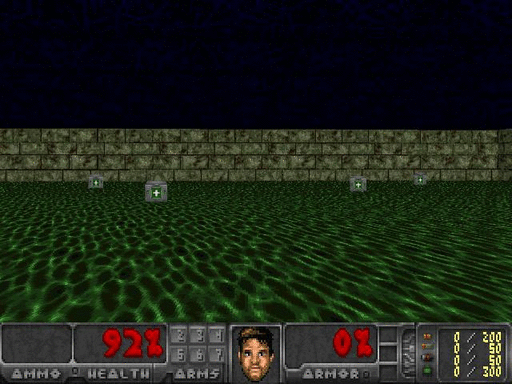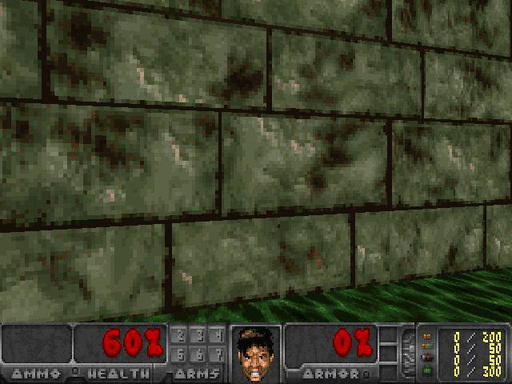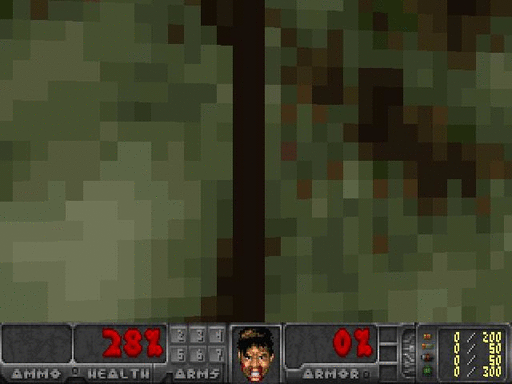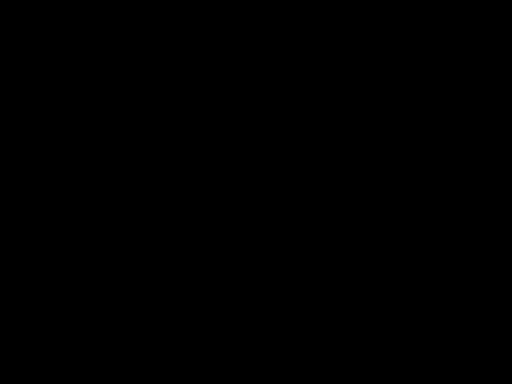
图2.采取随机行动的智能体,由Justin Francis提供
建立我们的机器学习环境
Reinforce被认为是一种蒙特卡洛学习法,这意味着,我们将收集整个实验的数据,然后在实验结束时进行计算。 在这个例子里,我们会收集一批数据来训练。 我们将把我们的环境训练数据设置为空白列表,在每一步结束时,我们会把数据附加(append)到这些列表中去
states , actions , rewards = [], [], []
接下来,定义一些我们所使用的神经网络将用到的超参数。
# Hyper Parameters
alpha = 1e-4
gamma = 0.99
Alpha是我们一般说的学习率,gamma是我们的奖励贴现率。 奖励贴现是一种度量未来潜在总奖励的方法,它是基于智能体的历史行为所获得的奖励进行估计的。如果贴现率趋近于0,那么智能体就会变得只关心即时奖励,而不考虑未来的潜在回报。 我们可以写一个简单的函数,在一次跑通关的场景下评估一组奖励,具体如下:
def discount ( r , gamma , normal ):
discount = np . zeros_like ( r )
G = 0.0
for i in reversed ( range ( 0 , len ( r ))):
G = G * gamma + r [ i ]
discount [ i ] = G
# Normalize
if normal :
mean = np . mean ( discount )
std = np . std ( discount )
discount = ( discount – mean ) / ( std )
return discount
我们来评估下面几组奖励:
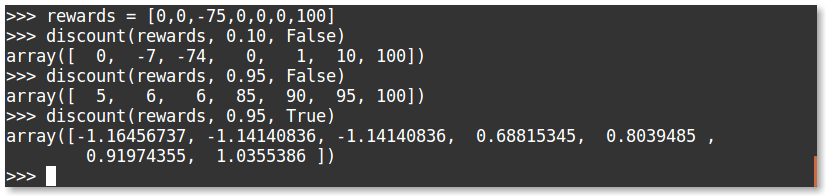
可以观察到,高贴现率的存在,导致了由于场景的结尾存在大额奖励,中间出现的大量惩罚都被忽视了。 我们还可以给我们『贴现后总奖励』加入标准化,以确保奖励的取值范围较小,这对在DOOM游戏环境中解决问题是至关重要的。
我们的价值函数将不断地对任何状态下的『贴现后总奖励』进行估计。
建立卷积神经网络
接下来,我们将建立卷积神经网络,以状态进行输入,并输出动作概率和状态的价值。 我们会有三个动作可供选择:前进,右移,左移。 策略近似(policy approximation)的设计与图像分类完全相同,不同之处在于,图像分类的输出是每个类别的置信度(概率),我们的输出将代表我们对采取某种行动的信心。 与大型图像分类模型相比,在强化学习领域,简单的网络模型效果最佳。
我们将使用和大名鼎鼎的DQN算法类似的方法,使用convnet。 我们的神经网络会把经过处理、调整完大小的84×84像素的图像作为输入,通过一个16通道,卷积核为8×8,步长为4的卷积,再接着一个32个通道,卷积核为8×8内核,步长为4的卷积,最后接一个有256个神经元的全连接层。对于卷积层,我们将使用VALID填充选项,这会很激进地让图像特征的尺寸变小。
我们的策略逼近函数以及价值逼近函数将共享相同的卷积神经网络来计算求值。
# Conv Layers
convs = [ 32 ]
kerns = [ 8 ]
strides = [ 4 ]
pads = ‘valid’
fc = 256
activ = tf . nn . elu
# Policy Network
conv1 = tf . layers . conv2d (
inputs = X ,
filters = convs [ 0 ],
kernel_size = kerns [ 0 ],
strides = strides [ 0 ],
padding = pads ,
activation = activation ,
name = ‘conv1’ )
conv2 = tf . layers . conv2d (
inputs = conv1 ,
filters = convs [ 1 ],
kernel_size = kerns [ 1 ],
strides = strides [ 1 ],
padding = pads ,
activation = activation ,
name = ‘conv2’ )
flat = tf . layers . flatten ( conv2 )
dense = tf . layers . dense (
inputs = flat ,
units = fc ,
activation = activation ,
name = ‘fc’ )
logits = tf . layers . dense (
inputs = dense ,
units = n_actions ,
name = ‘logits’ )
value = tf . layers . dense (
inputs = dense ,
units = 1 ,
name = ‘value’ )
calc_action = tf . multinomial ( logits , 1 )
aprob = tf . nn . softmax ( logits )
action_logprob = tf . nn . log_softmax ( logits )
在深度学习中,权重初始化非常重要。默认情况下, tf.layers将使用glorot均匀分布初始化函数(有时也称为xavier初始化)来初始化权重。 如果初始化的权重方差过大,则智能体的行为会发生系统性偏差,如果方差过小,那么智能体的行为会非常随机。 理想情况下,智能体在一开始会采取随机的行为,然后慢慢地改变权重,以获得奖励的最大化。 在强化学习中,这就是所谓的探索与开发(Exploration vs. Exploitation),因为一开始,智能体会随机地探索环境,并且在每次更新后,会把行动决策的概率更多的分配给那些倾向于获得良好奖励的行动。
度量和提高算法的表现
现在我们已经建立了模型,我们将如何让它去学习?答案非常简单。我们想要改变网络的权重,这样就会增加其采取某种行动的置信度,对权重改变的值基于我们对价值函数估计的准确度。 一言以蔽之,我们需要尽量减少我们的总损失。
为了在TensorFlow中实现这种方法,我们通过使用sparse_softmax_cross_entropy函数来度量我们的策略损失。这里的『稀疏』(sparse),意味着我们的行动的标签是整数,而logits是我们未经过激发的策略输出数值。这个函数为我们先计算softmax,再求对数损失(log loss)。 如果采取一个行动的信心/置信度接近1,那么对应的损失接近0。
然后,我们将交叉熵损失乘以贴现后总奖励与我们计算的价值估计之差。 我们再使用常见的均方误差损失函数来计算我们的价值损失函数。 然后我们把损失加在一起来计算我们的总损失。
# Define Losses
pg_loss = tf . reduce_mean (( D_R – value ) * sparse_softmax_cross_entropy_with_logits ( logits = logits , labels = Y ))
value_loss = value_scale * tf . reduce_mean ( reduce_mean ( D_R – value ))
entropy_loss = – entropy_scale * tf . reduce_sum ( aprob * aprob ( aprob ))
loss = pg_loss + value_loss – entropy_loss
# Create Optimizer
optimizer = tf . train . AdamOptimizer ( alpha )
grads = tf . gradients ( loss , trainable_variables ())
grads , _ = tf . clip_by_global_norm ( clip_by_global_norm , gradient_clip ) # gradient clipping
grads_and_vars = list ( zip ( grads_and_vars ()))
train_op = optimizer . apply_gradients ( grads_and_vars )
# Initialize Session
sess = tf . Session ()
init = tf . global_variables_initializer ()
sess . run ( init )
训练智能体
我们现在准备好训练游戏智能体了。 我们把当前状态输入神经网络,并通过调用tf.multinomial函数来获取我们需要采取的行动。 我们执行这一行动,并把状态,行动和未来的奖励进行存储。然后,我们将新调整大小的state2作为我们当前的状态存储,并不断重复此过程直到游戏结束。 我们会将状态,行动和奖励数据添加到一个新的列表中,使用这个数据输入到网络中进行一个批次(batch)的评估。
根据我们所使用的权重初始化方法,我们的智能体最终应该会训练200个批次,达到一个平均奖励为1200的水平,求解完这个虚拟环境。 对于这个环境,OpenAI给出的解决问题的标准是:连续100次平均奖励超过1000。如果允许智能体进行时间更久的训练的话,平均奖励值能达到1700,似乎无法达到更高的平均值了。这是我的智能体经过1000个批次的训练达到的效果:
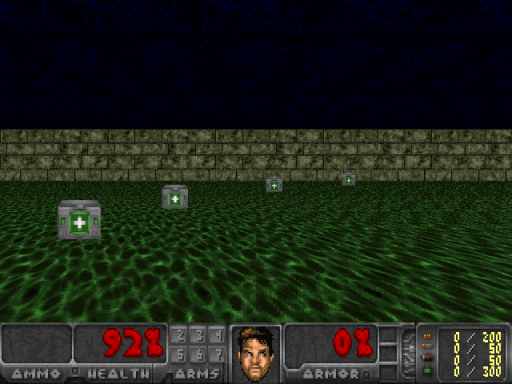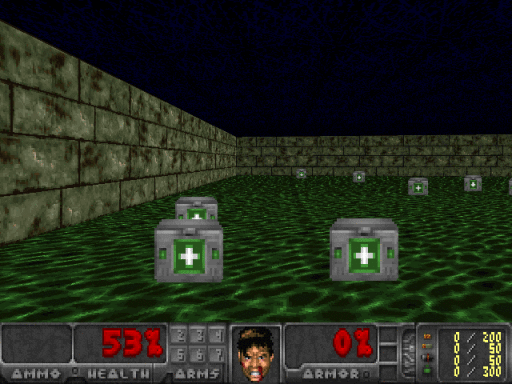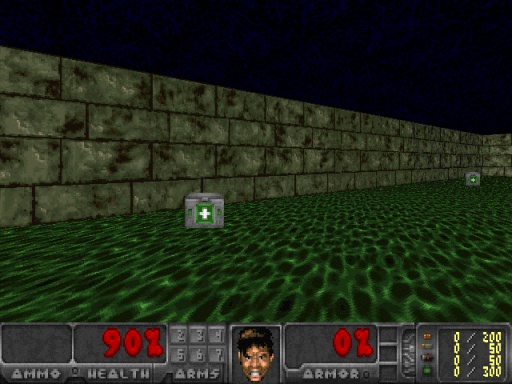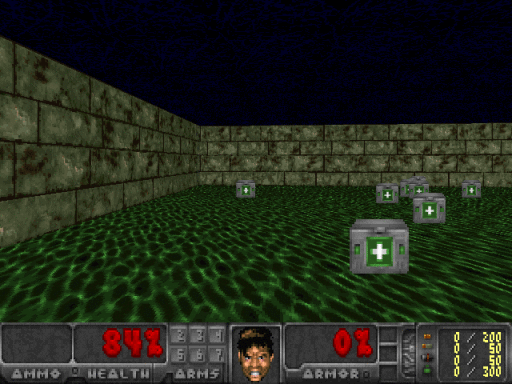
图3.Justin Francis训练了1000个批次之后的模型效果。感谢Justin Francis提供图片
如果你想在任意给定的图像帧上测试你的智能体,你需要做的,就是把这个状态输入网络,并观察输出。 如下所示,如果智能体正在面对一堵墙壁,有90%的置信度认为最好的行动是右转。而在下图最右侧的图片中,智能体只有61%的置信度认为向前进是最好的行动。
图4.对不同状态进行比较,感谢Justin Francis提供图片
如果你心思比较敏锐的话,你可能会认为61%的置信概率似乎是一个显然是『不错』,却并不是那么好的行动。你这么想就对了。 我怀疑我们的智能体学习到的主要目标,是避免撞到墙上;而且由于智能体只能通过存活来获取奖励,所以它并不是专门去拿医疗包,拾起医疗包只是为了苟延残喘。在某种意义上,我不会认为这个智能体是完全智能的。这个智能体也几乎完全不考虑左转这种行动。它拥有了一个简单的策略,它是自己学习到的,而且十分有效!
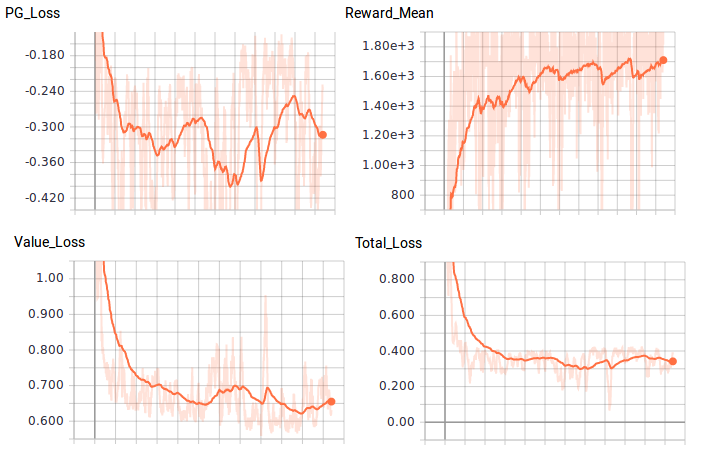
图5.对损失函数和奖励函数的比较。感谢Justin Francis提供图片
更进一步
所以,我希望你现在了解了策略梯度方法的基础知识。 这些是更高级的策略梯度法的基础,高级方法包括Advantage Actor-Critic方法, A3C或PPO等等。 Reinforce模型不考虑状态迁移(state transitions),动作价值(action values)或TD错误。 它也需要处理信任分配(credit assignment)问题。 要解决这些问题,您需要多个神经网络和更多的智能体训练数据。 还有很多实验可以用来提高模型性能,比如调整超参数。 通过一些比较小的修改,你可以使用这个完全一样的神经网络来解决很多Atari游戏。 所以,自己去尝试看看你能解决多少问题吧!
这篇博文是O’Reilly和TensorFlow的合作产物。请阅读我们的编辑独立声明。

Justin Francis
Justin Francis目前是加拿大Alberta大学的本科生。 Justin在其所在大学的工程俱乐部『自动驾驶机器人汽车项目』(arvp.org)的软件团队中,帮助他人进行深度学习和强化学习算法的实验和部署。 在更早之前,他是一个非营利的『社区合作自行车店』的创始人和教育家,并且花了两年的时间在帆船上对格鲁吉亚海峡进行探索和体验。






更多人工智能内容请关注2018年4月10-13日人工智能北京大会。