一个机器人向前迈了一大步然后跌倒了。下一次它就往前走一小步并可以保持平衡了。机器人就像这样尝试了很多次,最终它成功学会了正确的步伐大小并能够稳定地行走了。
我们看到的上述例子被称为增强学习。它将一个机器人的动作跟结果直接联系起来,而不需要学习复杂的机器人动作跟结果的关系。机器人基于动作带来的奖励(保持平衡)和惩罚(跌倒)来学习如何行走。这种反馈被称作对“做”或者“不做”某一种动作的“增强”。
在围棋中也可以找到使用增强学习的例子。如果计算机将它的白子放在某个位置,然后被黑子包围并丢失了该位置。那么该位置的走子方式就被惩罚。在多次被惩罚以后,当该位置有黑子包围时计算机就会避免将白子放到这个位置。
增强学习的一个简单定义就是学习基于奖励或惩罚的最佳动作。
在增强学习中有三个概念:状态、动作和回报。“状态”是描述当前情况的。对一个正在学习行走的机器人来说,状态是它的两条腿的位置。对一个围棋程序来说,状态是棋盘上所有棋子的位置。
“动作”是一个智能体在每个状态中可以做的事情。给定一个机器人两条腿的状态或位置,它可以在一定距离内走几步。通常一个智能体只能采取有限或者固定范围内的动作。例如一个机器人的步幅只能是0.01米到1米,而围棋程序只能将它的棋子放在19×19路棋盘(361个位置)的某一位置。
当一个机器人在某种状态下采取某种动作时,它会收到一个回报。这里的术语“回报”是一个描述来自外界的反馈的抽象概念。回报可以是正面的或者负面的。当回报是正面的时候,它对应于我们常规意义上的奖励。当回报是负面的时候,它就对应于我们通常所说的惩罚。
这些概念看起来都很简单直接:我们一旦知道了状态,就可以去选择一个(希望)能带来正面回报的动作。然而现实却复杂的多。
举一个机器人通过学习穿越迷宫的例子。当机器人向右移动一步时它到达一个活路的位置,然而当它向左移动一步时也到达一个活路的位置。机器人连续向左走了三步后它撞到了墙。回想起来在位置1采取向左行走是一个坏主意(坏动作)。那么机器人是如何在每个位置(状态)利用回报信息来学习穿越迷宫的(这是最终目标)?
“真正”的增强学习或者当前用作机器学习方法的增强学习版本,都关注自己的长期回报而不仅仅是当前的即时回报。
长期回报是在一个智能体跟外界交互时通过许多试错中学习到的。一个走迷宫的机器人会记住它撞到的每面墙。最后它会记住进入死胡同之前那些行走动作。它还会记住成功通过迷宫的行走路径(行走动作的序列)。增强学习的基本目标就是学习一个有长期回报的动作序列。智能体是通过跟外界交互并观察每个状态下的回报来学习动作序列的。
智能体是如何知道期望的长期受益?秘密在于Q表(Q函数)。Q表是一个用于 “回报”与每个“状态-动作”组的对应关系的查找表。此表中的每个单元格记录了一个称为Q值的数值。它表示智能体在特定状态下采取这个动作时得到的长期回报,以及随后选择可能的最佳路径。
智能体是如何学习这个长期回报Q值的?事实证明智能体不需要解一个复杂的数学方程。它只需要一个简单的被称为Q学习的过程来学习所有的Q值。增强学习的本质就是学习采取动作时的Q值。
Q学习:一种常用的增强学习方法
Q学习是最常用的增强学习方法,其中Q代表某种动作的长期回报价值。 Q学习是通过观察来学习Q值的。
Q学习的过程是:
开始时智能体会把每个“状态-动作”组的Q值初始化为0。更精确的描述为对所有的状态s和动作a:Q(s,a)=0。这从本质上说我们不知道关于每个“状态-动作”组的长期回报信息。
在智能体开始学习后,它会在状态s下采取动作a并获得回报r。它的状态会变成状态s’。智能体会用以下公式更新Q(s,a):
Q(s,a) = (1-学习速率)*Q(s,a)+学习速率*(r+折扣率*max_a(Q(s’,a)))
学习速率是介于0到1之间的数值。它是新回报信息和旧回报信息之间的权衡权重。假设该智能体接下来都一直采取最佳的动作,新的长期回报就是当前回报r加上下一个状态s’及以后所有状态下的未来回报。未来回报会用一个介于0到1之间的折扣率来打折,这意味着未来回报没有当前回报的影响大。
在该更新方法中,Q值包含了过去的回报信息并把未来的动作也考虑进来。注意假设往后我们一直都走最优的路径,我们使用最大化的Q值作为新的状态。当智能体到达所有状态并尝试了不同的动作时,它最终可以为所有可能的“状态-动作“组学习一个最优的Q值。然后它可以推断出长期来说每个状态下的最优动作。
以下是一个机器人走迷宫的简单例子:
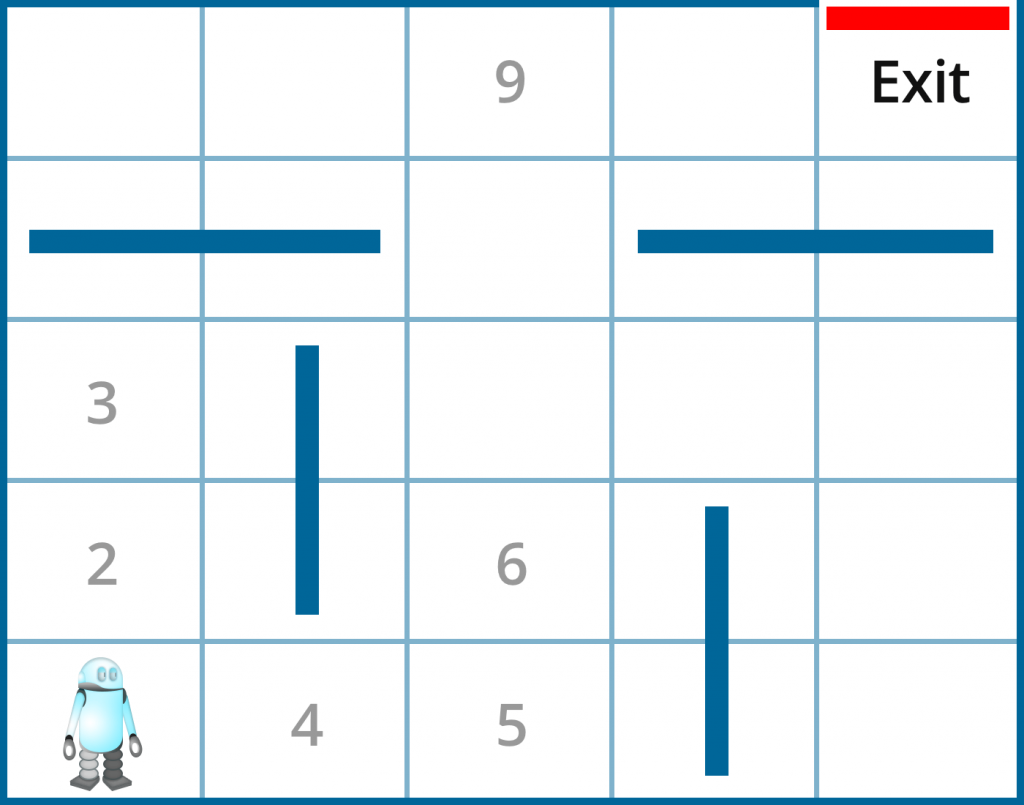
图1. 一个机器人通过学习穿越迷宫的路径
机器人从迷宫的左下角开始。每个位置(状态)由数字表示。有上下左右四种动作可以选择,但在某些状态下动作的选择是有限制的。例如在状态1(初始状态),机器人只有两种选择:上或右。在状态4机器人有3种选择:左、右或上。当机器人碰到墙时,它会收到回报值-1。当它到达一个活路位置时,它会收到回报值100。注意这种一次性的回报值跟Q值是非常不同的。事实上我们是这样计算Q值的:
Q(4,左) = 0.8*0+0.2*(0+0.9*Q(1,右))
Q(4,右) = 0.8*0+0.2*(0+0.9*Q(5,上))
其中学习效率为0.2而折扣率为0.9。状态1的最佳动作是向右,状态5的最佳动作是向上。Q(1,右)和Q(5,上)有不同的值是因为它从状态1比从状态5到达出口需要走更多步。由于我们会对未来的回报打折扣,所以我们会把为实现目标多走的步数打折扣,因此Q(5,上)会比Q(1,右)的值更高。从而Q(4,右)比Q(4,左)的值更大,所以状态4的最佳动作是向右。
Q学习需要智能体不断尝试来遍历所有可能的“状态-动作”组。只有那时智能体才能够对这个世界有个完整的印象。Q值表示采取最佳动作序列时的最优值。这个动作序列也被称为“策略”。
我们面临的一个根本问题是:当智能体在一个给定的环境中探索可能的动作时,它有可能学习所有的Q值吗?换句话说这样的学习是否可行?如果外界能对智能体的动作做出反馈的话,答案是肯定。换句话说,状态是基于动作而改变的。这样的假设被称为马尔科夫决策过程(MDP)。这一过程假设下一状态是由之前的状态和采取的动作决定的。基于这一假设,所有可能的状态最终都会到达并且可以确定每个“状态-动作”组的长期回报值(Q值)。
想象一下我们生活在一个随机的世界中,我们的行为对接下来发生的事没有影响。那么增强学习(Q学习)就会失效了,经过多次尝试以后,我们不得不认输放弃。幸运的是我们的世界更具有可预测性。例如当一个围棋选手将棋子放在棋盘上的某个位置时,下一轮时棋子的位置就很明确了。我们的智能体跟外界环境交互并通过行动来塑造外界环境。智能体在某种状态下的动作的确切影响通常是直接明了的。新状态是可以立即观测到的。机器人可以知道它应该在哪里结束学习。
增强学习的常用技术
增强学习的基本技术是探索与利用。智能体在状态s中对于每个动作a学习Q(s,a)的值。由于智能体需要得到一个高的回报值,它可以基于当前的回报信息来选择能够得到最高回报值的动作(利用),或者不断尝试新的动作以期望能有更高的回报(探索)。当一个智能体在线(实时)学习时,这两种策略的平衡是非常重要的。这是因为智能体在实时学习时必须使自己能够维持生存(如探索一个洞穴或者在战斗中对抗时),并能找到最佳动作。当一个智能体离线学习时(这意味着不是实时的),这种策略平衡不需要过多考虑。在机器学习术语中,离线学习意味着一个智能体不需要跟外界环境交互就可以处理信息。在这种情况下当智能体尝试(探索)许多不同的动作时,不用担心后果,失败(像撞到一堵墙或者在一个游戏中被打败)的代价会很低。
Q学习的性能取决于访问所有“状态-动作“组以学习正确的Q值的数量。这在状态量比较少的时候是可以轻易实现的。然而在现实世界中,状态的数量可能非常大,特别是当系统中有多个智能体时。例如在迷宫游戏中,一个机器人最多有1000个状态(位置)。当它跟另外一个机器人比赛时状态数量会增长到1000000,这里的状态表示两个机器人的联合位置(1000×1000)。
当状态空间很大时,等待我们访问完所有的“状态-动作”组是没有效率的方法。有一种更快速的方法叫做蒙特卡罗方法。在统计学中,蒙特卡罗方法通过重复采样得到一个平均值。在增强学习中,蒙特卡罗方法用于在重复观察相同的“状态-动作”组之后计算Q值。这种方法将Q值Q(s,a)定义为多次访问相同的“状态-动作”组(s,a)后的平均回报。这种方法不需要使用学习速率或折扣率。它只依赖于大量的模拟。由于其简便性,这种方法变的非常流行。它已经被AlphaGo用于跟自己对弈很多次以后来学习最佳走子方式。
减少状态数的另外一种方法是使用神经网络,其中输入是状态而输出是动作或者是跟每个动作相关联的Q值。深度神经网络能够通过隐藏层极大地简化状态表示。在这篇关于应用于Atari游戏的深度增强学习的《Nature》论文中,整个游戏局面通过一个卷积神经网络映射以确定Q值。
增强学习善于做什么?
增强学习在关于外界信息是非常有限的情况时的场景是有用的:特别是没有给定的世界地图。这时我们不得不通过跟外界环境交互来学习我们的动作:需要不断地试错。例如围棋程序不能计算所有可能的状态(10^170种)。宇宙的年龄只有10^17秒,这意味着计算机即使可以在一秒内计算十亿(10^9)种可能的局面(状态),围棋程序也要用比宇宙年龄更长的时间来完成计算。
由于我们不能列出所有可能的情况(并相应的优化我们的动作),因此我们需要通过行作的过程来学习。一旦采取了某个动作,我们可以立即观察结果并改变下一次的动作。
最近的应用
传统上增强学习主要应用于机器人控制和简单的棋类游戏,例如西洋双路棋。最近增强学习跟深度学习相结合的方法有很强劲的势头,它可以在状态数非常多的时候简化状态。当前增强学习的应用包括:
1. 围棋游戏
最成功的例子是AlphaGo,它是一个赢了排名世界第二的人类围棋选手的计算机程序。AlphaGo使用增强学习并基于当前棋盘局面来学习下一步走子方式。棋盘局面通过卷积神经网络被简化,之后产生走子方式作为输出。
2. 电脑游戏
最近在Atari游戏中应用到了增强学习。
3. 机器人控制
机器人可以使用增强学习来学习走路、跑步、跳舞、飞行、打乒乓球或者堆乐高。
4. 在线广告
计算机程序可以使用增强学习选择在正确的时间或者以正确的格式向用户显示广告。
5. 对话生成
会话智能体会基于前瞻性的长期回报来选择要说的句子。这使得对话更具有吸引力并能持续时间更长。例如程序回答“你多大了”这个问题时可以说“我16岁了,你为什么要问这个问题?”,而不是只说”我16岁了”。
增强学习入门
OpenAI提供了一个增强学习的基准工具包OpenAI Gym。它包含示例代码,可以帮助初学者入门。其中CartPole问题是一个有趣的入门问题,很多学习者都提交了他们关于这个问题的代码和相关文档。
AlphaGo及其应用增强学习的成功提高了人们对这种方法的兴趣。强化学习通过跟深度学习相结合已经成为许多应用的强大工具。增强学习的时代到来了!






更多内容可以参考Strata北京2017的相关议题。