NumPy的重要特性之一是能够执行快速的元素级运算,既有基本的算术(加减乘除等),也有更为复杂的运算(三角函数、指数和对数等方法)。Pandas从NumPy继承了这些功能中的大部分,我们在第X.X节中介绍过的通用处理函数(universal functions简称ufuncs)是关键所在。
Pandas包含了一些有用的应变:对于像否运算以及三角函数这样的一元运算,这些通用方法在输出中会保留索引和列标签。而对于加法和乘法这样的二元运算来说,Pandas将会在对象传到方法中的时候自动对齐索引。这意味着保留数据的上下文以及组合来自不同源的数据—这两个在原始NumPy数组中容易出错的任务,在Pandas中几乎可以做到万无一失。此外,我们还将看到Pandas包含非常好的可以在一维Series结构以及二维DataFrame结构之间进行的运算。
Ufuncs:索引保留
因为Pandas是被设计和NumPy一起工作的,任何NumPy的ufunc将都可以在Pandas Series对象和DataFrame对象上使用。我们从定义一个简单的Series和DataFrame开始:
import pandas as pd import numpy as np
rng = np.random.RandomState(42) ser = pd.Series(rng.randint(0, 10, 4)) ser
df = pd.DataFrame(rng.randint(0, 10, (3, 4)), columns=['A', 'B', 'C', 'D']) df
如果我们将一个NumPy通用函数应用到这些对象上,其结果将会是另外一个保留索引的Pandas对象:
np.exp(ser)
或者,对于一个稍微复杂的计算:
np.sin(df * np.pi / 4)
任何在第X.X节中讨论过的通用函数都可以这样使用。
Ufuncs:索引对齐
对于在两个Series或者DataFrame之间进行的二元操作,Pandas将会在执行操作的过程中将索引对齐。在处理不完整数据的时候,这是非常便捷的,正如我们下面的几个例子所要展示的。
Series中的索引对齐
作为一个例子,假设我们正在组合两个不同的数据源,并且发现只有美国面积排名前三的州和美国人口排名前三的州:
area = pd.Series({'Alaska': 1723337, 'Texas': 695662,
'California': 423967}, name='area')
population = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127}, name='population')
我们来看一下当我们将人口除以面积来计算人口密度是会发生什么:
population / area
结果数组包含了两个输入数组的索引并集,这可以通过使用标准的Python集合运算来得到:
area.index | population.index
任何在一个或者另一个数组中没有输入的项将会被标记成NaN(“Not a Number”,不是一个数字),Pandas就是这样标记缺失数据的(更多的关于缺失数据处理的讨论请看第X.X节)。这一索引匹配对于任何Python内置算术表达式都是这样实现的,任何缺失值默认将被NaN填充。
A = pd.Series([2, 4, 6], index=[0, 1, 2]) B = pd.Series([1, 3, 5], index=[1, 2, 3]) A + B
如果填充NaN值不是所期望的行为,那么填充的值可以被修改,只要使用恰当的对象方法来代替操作符。例如,调用A.add(B) 与调用A + B是等价的,但是前者允许可选的定义明确的填充值。
A.add(B, fill_value=0)
DataFrame中的索引对齐
当在DataFrame上执行运算时,类似的对齐将同时发生在列和索引上:
A = pd.DataFrame(rng.randint(0, 20, (2, 2)),
columns=list('AB'))
A
B = pd.DataFrame(rng.randint(0, 10, (3, 3)),
columns=list('BAC'))
B
A + B
请注意,不论在两个对象中的索引的排列顺序如何,索引都可以正确对齐,并且在结果中索引是已排序的。与Series的情况相似,我们可以使用对象的运算方法并且传递任何想要的填充值来代替缺失的输入:
A.add(B, fill_value=np.mean(A.values))
Python运算和与它们等价的Pandas对象方法的表格如下:
|
Operator |
Pandas Method(s) |
|
+ |
add() |
|
– |
sub(), subtract() |
|
* |
mul(), multiply() |
|
/ |
truediv(), div(), divide() |
|
// |
floordiv() |
|
% |
mod() |
|
** |
pow() |
Ufuncs:在DataFrame和Series之间的运算
当在一个DataFrame和一个Series之间执行运算时,索引和列对齐也会被类似地处理。在一个DataFrame和一个Series对象之间的运算与二维和一维NumPy数组之间的运算类似。比如一个常见的运算,获得一个二维数组和它其中一行之间的差集:
A = rng.randint(10, size=(3, 4)) A
A - A[0]
根据NumPy的传播规则(参见第X.X节),在一个二维数组和它的一行之间的减运算是行级应用的。
在Pandas中,默认情况下是类似的,该运算也是行级的。
df = pd.DataFrame(A, columns=list('QRST'))
df - df.iloc[0]
如果你想要以列级的方式来运算,你可以使用上面提到的对象方法,指定轴关键字:
df.subtract(df['R'], axis=0)
请注意,这些DataFrame/Series运算,与上面讨论过的运算一样,将会自动对齐两个元素中的索引。
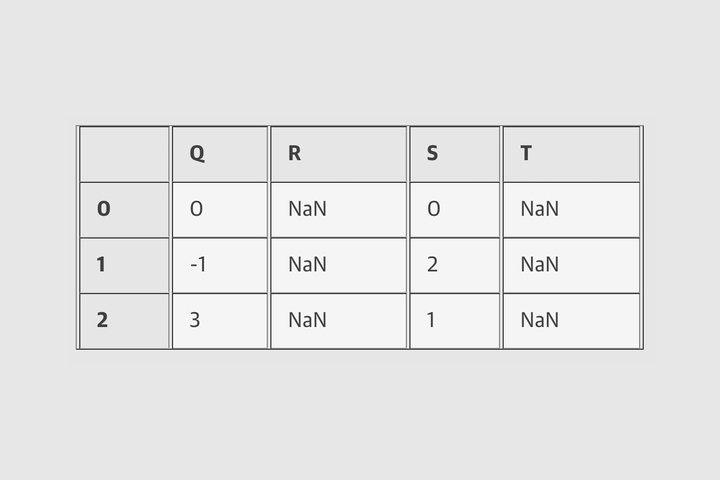
halfrow = df.iloc[0, ::2] half row
df – half row
这种索引及列的保留和对齐意味着在Pandas中对于数据的操作将总会维护数据的上下文,从而避免在处理原始NumPy数组里的异构数据时可能出现的各类愚蠢的错误。
总结
我们已经展示了标准的NumPy通用方法将会元素级地计算Pandas对象,并具有一些额外的有用的功能:它们保留索引名和列名,同时自动将不同的索引集合和列集合进行对齐。与我们在前面章节看到的基本索引和选择运算类似,这些在Series和DataFrame上的元素级运算构成了许多更加复杂的数据处理实例的基石。这里要特别提一下索引的对齐操作,有时候会导致一些值在结果数组中是缺失的。下面一章我们将详细讨论Pandas是如何选择处理这类缺失数据的。

杰克•范德普拉斯(Jake VanderPlas)
杰克•范德普拉斯是Python科学计算组件的长期用户和开发者。他现在是华盛顿大学跨学科研究主管,他主要进行他自己的天文学研究,并在各个领域为的科学家提供建议和咨询。