在之前的一篇文章中我们讨论了机器学习(ML)在软件开发中的应用,其中包括数据科学中的采样工具和管理数据基础架构。 从那时起,Andrej Karpathy就软件开发的命运做出了更多的预测:他设想了软件2.0,其中软件开发的本质已经发生了根本性的变化。 人类不再实施解决业务问题的代码; 相反,他们定义了所需的行为,训练算法来解决他们的问题。 正如他所写的那样,“神经网络是一段这样的代码,在绝大部分垂直领域,它比你我表现都要好。” 我们不会编写代码来优化制造工厂的调度工作,我们将训练ML算法,以根据历史数据找到具有最佳性能的方案。
如果不再需要人类编写企业应用程序,我们该怎么办? 人类仍然需要编写软件,但该软件是一种全然不同的类型。 Software 1.0的开发人员拥有大量可供选择的工具:IDE,CI / CD工具,自动化测试工具等。 软件2.0的工具才刚刚开始存在;未来两年的一项重大任务是开发用于机器学习的IDE,以及用于数据管理,流水线管理,数据清理,数据源头管理和数据出处的其他工具。
Karpathy的愿景雄心勃勃,我们认为企业软件开发人员在短时间内担心丢掉工作。 但是,显然软件的开发方式正在发生变化。 通过机器学习,挑战不在于编写代码;算法已经在许多众所周知且高度优化的库中具有实现了。 我们不需要实现我们自己的算法版本,比如长短时记忆模型(LSTM)、强化学习;这些我们能从PyTorch,Ray RLlib或其他一些库中获得。 但是,没有数据就无法进行机器学习,而且我们处理数据的工具也不够用。 我们有很好的工具来处理代码:创建代码,管理代码,测试代码和部署代码。 但是它们并没有解决数据问题,而对于ML来说,管理数据与管理代码本身一样重要。 GitHub是一个管理代码的优秀工具,但我们需要考虑[代码+数据]。 虽然我们开始看到机器学习模型的版本控制项目,例如DVC,不过不存在一个数据领域的Github。
精确思考git的作用非常重要。 它能捕获源代码以及源代码的所有更改。 对于任何代码库,它可以告诉您代码从哪里来(来源),以及从原始提交到您下载的版本的所有更改。 它能够维护许多不同的分支,反映了一份代码的多种定制化情况。 如果某人更改了一行代码,您将看到该更改,以及是谁更改了代码。 并且(在人工的帮助或者辛苦劳动下)可以解决不同分支上的冲突。 这些功能对数据都很重要,但是git虽好,却不适合数据。 它没有格式化为一系列行的数据(如源代码),在处理二进制数据上存在问题,并且会在巨大的文件上卡住。它也不适合跟踪数据集中对每个样本进行的变换,例如矩阵乘法或归一化。
我们还需要更好的工具来收集数据。 我们听过了所有关于数据大爆炸的讨论,讽刺的是,爆炸性的巨量数据被丢掉了,从来没有被捕获过。数据管理不仅限于数据来源和数据出处等问题;处理数据,最重要的事情之一是收集它。 考虑到创建数据的速率,数据收集必须自动化。 如何在不丢弃数据的情况下做到这一点? 鉴于任何模型产生的预测结果都会代表用于创建模型的数据,您如何确保您的数据收集过程是公平的,有代表性的和无偏见的?
通往可持续的ML实践
在我们即将发布的《数据基础架构的演进》这一报告中,我们研究的一个方面是,欧洲组织正在采取哪些措施来构建可持续的机器学习实践:当下一个技术潮流出现时,我们不需要一个概念上的论证,或是一次性的好点子,我们需要而是组织计划中能够永存的那部分。 点到为止是一回事,将机器学习深度集成到您的组织中所需的基础架构中,就完全是另一回事了。
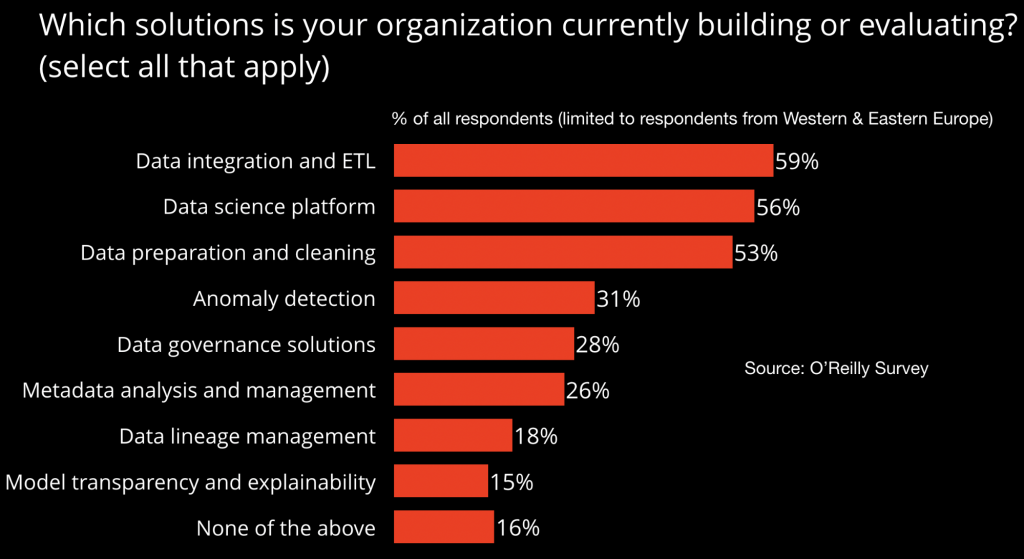
建立可持续的实践意味着要把时间精力投资于能够让您长期有效工作的工具。 这些工具使您能够构建可依赖的软件,而不仅仅是简单的概念验证级别的拷贝。这些工具包括ETL等基础工具(提取,转换和加载:从多个源提取数据,将其转换为有用的形式,并将其加载到数据存储区进行分析)。 毫无疑问,公司正在投资数据科学平台以大规模运行机器学习,就像他们十年前投资Hadoop一样。 鉴于数据科学家的大部分工作是在分析之前清理数据,因此大多数公司都花精力在数据准备工具上并不奇怪。 随着公司开始构建数据科学实践,这些是五年前我们期望在列表中看到的工具。
我们也看到了对新工具的投资。 异常检测工具在金融行业中是普遍的,它经常用于检测欺诈性交易,但它也可用于自动捕获和修复数据质量问题。 这并不奇怪: 如果您从多个气象站收集数据并且其中一个发生故障,您可能会看到异常数据。 有故障的气象站可能会停止报告数据(可能会在数据流中变为零,无穷大或空值),或者它可能只发送比预期高几度的读数,但是与该地区中其他站点的读数不一致。 在任何情况下,输入数据都可能会出现异常,机器检测异常会比人类更容易。 如果您突然在社交数据中看到意外模式,则可能意味着攻击者试图破坏您的数据源。 异常检测可能起源于金融,但它正在成为每个数据科学家工具包的一部分。
元数据分析可以构建数据目录,从而使人们能够发现与其项目相关的数据。对数据进行民主化是向成为数据驱动(或人工智能驱动)公司的过程迈出的重要一步:必须授权用户探索数据,并创建自己的项目。 没有某种数据目录性质的东西存在,事情就很难做。 您可以告诉用户他们可以访问他们需要的所有数据,并授予他们访问数据库的权限,但除非他们知道可用的数据是什么,以及如何找到它,否则这种访问毫无意义。手动创建该目录是不可能的;这个流程需要自动化。
数据出处
数据分析的历史一直受到对数据源的轻视态度的困扰。 这就是最终情况: 数据伦理的讨论使数据科学家意识到数据来源和数据出处的重要性。 两者都指的是数据来源:数据来自何处,如何收集,以及如何修改数据? 数据来源日益成为了一个法律问题: 知道数据来自何处以及如何获得数据显然非常重要。 当您组合来自多个来源的数据时,这一点尤其重要;我们经常观察到,当组合多个源时,数据最强大。 数据的起源可能变得非常复杂,特别是当一组数据产生的结果与其他数据进一步结合时尤为如此。
能够在细粒度级别跟踪数据出处,了解从源到应用程序的整个数据路径非常重要。数据一直在被修改:经常可以看到,数据科学的大部分工作都是清理或准备。 数据清理涉及修改数据:例如,消除具有缺失值或非法值的行。 我们开始清楚的认识到“清理过程中发生了什么,数据是如何从原始状态演变出来的” 这一重要性:这些过程可能是错误和偏见的来源。 随着公司采集和使用更多数据,并且随着数据消费者数量的增加,知道数据是值得信赖的这一点很重要。 修改数据时,确切地跟踪修改数据的方式和时间非常重要。
跟踪数据来源和沿袭的工具是有限的,尽管商业供应商(如Trifacta)的产品开始出现。 Git及其前身(SVN甚至RCS)可以跟踪软件中每行代码的每个变化,维护代码的多个分支,并协调分支之间的差异。 我们如何围绕数据做到这一点? 此外,我们将如何处理结果? 标准化数据或以某种方式进行转换是很常见的,但这种转换很容易改变数据集中的每个字节。
这些变化不仅会带来问题,而且像git这样的工具会在提交新版本来解释为何进行任何更改时强制人们提供解释性注释。 使用自动数据管道来实现这一点是不可能的。系统可能会记录并“解释”它们所做的更改,但这基于的假设是,您已经具有细粒度数据控制权而且强制它们这样做。
在单个工具的范围内,也许可以进行这种控制。 例如,Jacek Laskowski 描述了如何提取描述一系列Spark转换的弹性分布式数据集(RDD)数据血缘关系图。 该图可以提交出处跟踪系统,甚至是更传统的版本控制系统,以记录那些已经应用于数据的转换。 但是这个过程只适用于单个机器学习平台:Spark。为了变得更加有用,每个平台都需要支持提取血缘关系图,最好是采用单一格式,而不需要开发人员进行额外的脚本开发。 对于我们需要达到的目标来说,这是一个很好的愿景,但我们还没达到。
数据来源和出处关系不仅仅与结果的质量有关; 这是一个安全和合规问题。 在2017年纽约的Strata数据会议上,Danah Boyd认为,社交媒体系统故意被传播低质量内容的工具所毒害,这些内容旨在影响确定人们观看内容的算法。恶意的算法已经学会“破解注意力经济”。在“ 平面光:对迷失方向人群进行数据保护,从政策到实践”)这一研究报告中,Andrew Burt和Daniel Geer认为,过去数据准确性是二元的 —— 数据是正确的还是不正确的。 现在,数据来源如果不比数据的准确性更重要,那也至少是同样重要:如果您不知道数据来源,则无法判断数据是否可靠。 对于机器学习系统,这意味着我们需要跟踪源数据和源代码:用于训练系统的数据,和通过算法实现所表现出来的行为同样重要。
我们开始看到一些自动化数据质量问题的工具。 Intuit在检测数据中的异常时使用Circuit Breaker模式来暂停数据管道。 他们的工具跟踪数据出处,因为了解管道每个阶段的输入和输出非常重要; 它还跟踪管道组件本身的状态以及管道每个阶段的数据质量(是否在预期的范围内,是否属于适当的类型等)。Intuit,Netflix和Stitchfix构建了数据沿袭系统,可跟踪他们在系统中使用的数据的来源和演变。
自动化的含义远远大于模型构建
在过去的一年中,我们看到有几家公司构建了“自动化机器学习”的工具,包括谷歌和亚马逊。 这些工具能对构建模型的过程进行自动化:尝试不同的算法和拓扑,以便在模型用于测试数据时最大限度地减少错误。 但这些工具只是构建模型,我们已经看到机器学习需要更多。 没有用于数据集成和ETL,数据准备,数据清理,异常检测,数据治理等工具的模型,该模型就不可能存在。自动化模型构建只是机器学习自动化的一个组成部分。
为了真正有用,自动化机器学习必须比模型构建更深入。 认为机器学习项目需要单一模型太简单了; 一个项目可以轻松地需要几个不同的模型,做不同的事情。 业务的不同方面,虽然表面上相似,但可能需要不同的模型,并从不同的数据源进行训练。 考虑一下像万豪酒店这样的酒店业务:超过6,000家酒店,总收入超过200亿美元。 任何酒店都希望对他们的入住率,收入和需要提供的服务进行预测。 但每家酒店都提供了完全不同的业务:时代广场的万豪酒店以大型企业会议和纽约市旅游业为主,而塞巴斯托波尔的Fairfield Inn酒店则以当地活动和葡萄酒乡村旅游为主。 客户群人口学的统计数据不同,但更重要的是,活动事件的来源不同。 塞巴斯托波尔的酒店需要了解当地的婚礼和葡萄酒乡村活动,我预期他们会使用自然语言处理来解析当地报纸的信息。 时代广场的酒店需要了解百老汇开放,Yankee橄榄球队的比赛,以及城北地铁的时刻表。 这就不仅仅是一个不同的模型了,这两项业务需要完全不同的数据管道。 自动化模型构建过程很有帮助,但它还远远不够。
酒店不是唯一需要比人类想象需要构建的模型更多的商业模式。 Salesforce为其客户提供人工智能服务,其数量达数十万。 每个客户都需要一个定制模型,即使在类似企业的客户之间也无法共享模型。 除了机密性问题,没有两个客户拥有相同的客户或相同的数据,客户之间的微小差异可能会导致大的错误。 即使对机器学习人才最乐观的估计,也没有足够的人手动构建那么多模型。 Salesforce的解决方案是TransmogrifAI,一个用于结构化数据的开源自动化ML库。 与其他Auto ML解决方案一样,TransmogrifAI可以自动化模型构建过程,但它还可以自动执行许多其他任务 ,包括数据准备和特征验证。
其他企业软件供应商也都在同样的路上:他们拥有许多客户,每个客户都需要“定制模型”。他们无法聘请足够的数据科学家来支持所有这些客户使用传统的手动工作流程。 自动化根本不是一种选项,而是一种必需品。
当模型“完成”时,自动化不会停止; 在任何实际应用中,模型永远不会被视为“完成”。任何模型的性能都会随着时间的推移而降低:情况会发生变化,人们会发生变化,产品会发生变化,甚至模型本身都可能会成为模型变坏的因素。我们预期会看到用于自动化模型测试的新工具,要么在模型需要重新训练时提醒开发人员,要么自动启动训练过程。 我们需要更进一步:除了模型准确性的简单问题之外,我们还需要测试公平性和道德性。这些测试不能完全自动化,但我们可以开发工具来帮助领域专家和数据科学家发现公平性问题。 例如,这样的工具可能会在检测到潜在问题时生成警报,例如来自受保护组的显著更高的贷款拒绝率;它还可以提供工具来帮助人类专家分析问题并进行纠正。
结尾的思考
我们构建软件的方式正在发生变化。 无论我们是否使用Karpathy的软件2.0,我们当然都朝着这个方向前进。 未来会存在更多的机器学习,而非更少。开发和维护模型将是构建软件工作的一部分。 软件开发人员将花费更少的时间编写代码,并花更多时间训练模型。
不过,缺乏数据、缺乏处理数据的工具仍然是一个根本瓶颈。 在过去的50年中,我们开发了用于处理软件的出色工具。 我们现在需要构建软件+数据的工具:跟踪数据来源和血缘关系的工具,从元数据构建目录的工具,以及执行ETL等基本操作的工具。 很多公司正在投资这些基础技术。
下一个瓶颈将是建模本身; 我们需要的模型数量总是远远大于能够手动构建这些模型的人数。 同样,该解决方案正在构建用于自动化流程的工具。 我们需要做的不仅仅是使用AutoML自动化模型构建; 我们还需要在数据管道的每个阶段自动执行特征工程,数据准备和其他任务。 毕竟,软件开发人员从事的是一种自动化业务。 软件开发人员最需要自动化的,是他们自己的工作。
相关内容
- “机器学习对软件开发而言意味着什么”
- Vitaly Gordon谈“构建企业数据科学工具”
- Tim Kraska谈“机器学习如何加速数据管理系统”
- “为未来的AI应用构建工具”
- Mark Hammond 谈 “机器学习需要机器教学”
- Joe Hellerstein谈“元数据服务如何导致绩效和组织架构改进”








2019年6月18-21日在北京举行的人工智能大会议题征集正在进行中,将于1月15日结束。