 数据
数据
Radar


-

为什么Java、Python会进入程序员最怕编程语言榜单
在 StackOverflow 的 2020 年度开发者调查中有一张表格,显示的是“最受欢迎、最令人畏惧和最想要的编程语言”。最受欢迎的和最...
-
2020年技术领导人需要关注的5大关键领域
O’Reilly online learning平台上有很多关键信息,涉及到技术领导者需要关注的趋势和问题。这也是我们年度使用率研究的数据来...
-
无服务器计算中的两个缺失链条:有状态计算和放置位置控制
由于无服务器计算的易编程性和易管理,近年来它得到了迅速的普及。许多人将其视为云服的下一个通用计算平台[4]。 但是,虽然...
-
在企业里管理机器学习:来自银行和医疗行业的经验
随着企业在更广泛的产品和服务组件中使用机器学习(ML)和人工智能技术,对新的工具、最佳实践和新的组织结构的需求变得越来...
-
碰到语音数据了吗?这些指导意见将帮助你开始构建语音应用
随着企业开始进行人工智能技术的探索,三个特定的领域引起了很多关注:计算机视觉、自然语言应用和语音技术。世界知识产权局...
-
RISELab的AutoPandas暗示着自动化技术将改变软件开发的性质
关于人工智能有很多的炒作,但企业是否真地开始使用人工智能技术了?我们在今年早些时候发布的一项调查中发现,就职于企业的...
-
一张图表明:研究人员喜爱PyTorch和TensorFlow
在近期我们进行了一项调查——企业里的人工智能,收到了超过1300份的回复。我们发现几个机器学习的库和框架被广泛地使用。超过...
-
已改进的工具生态系统正在助推人工智能落地
在这篇文章中我分享了Roger Chen和我在2019年人工智能大会纽约站上发表的主题演讲中的幻灯片和备注。在这个简短的总结中,我...
-
成为一家机器学习公司意味着投资基础技术
在这篇文章中,我分享今年早些时候我在伦敦的Strata数据会议上发表主题演讲的幻灯片。我将重点介绍最近一项关于机器学习被采...
-
用于机器学习开发和模型治理的专用工具日益变得重要
几年前我们开始发布文章(参见本文末尾的“相关资源”),了解数据团队开始接受更多机器学习(ML)项目时所面临的挑战。 在此过...
-
对高质量数据的追求
“人工智能始于’好’数据”这种说法,得到了数据科学家、分析师和企业主的广泛认同。我们为预测、分类和各种分析任务构建复杂人...
-
AI和机器学习如何改善客户体验
人工智能(AI)和机器学习(ML)可以做些什么来改善客户体验? 自从网上购物诞生以来,AI和ML就已经和在线购物系统紧密结合了...











Learning

-
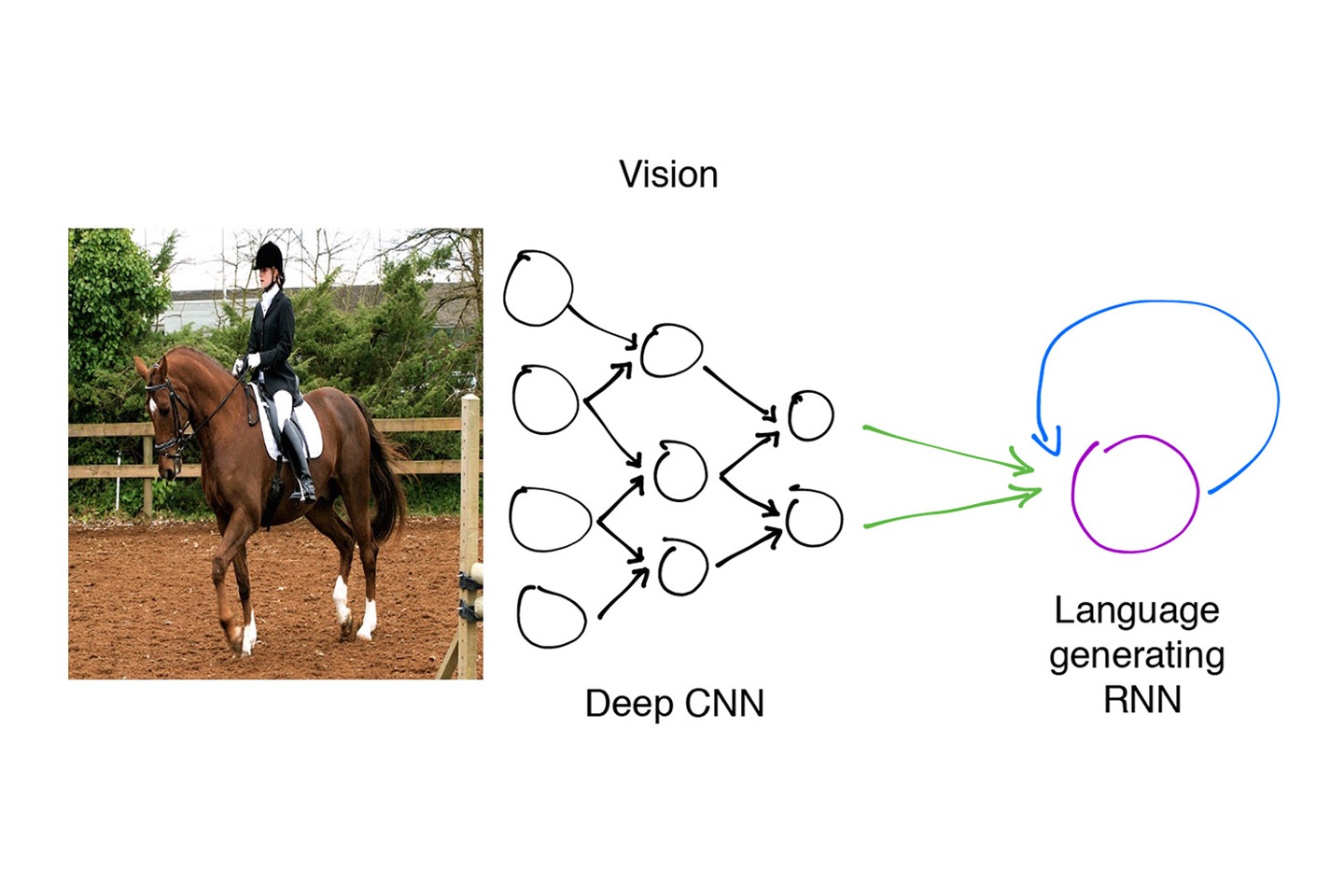
用TensorFlow为图片添加字幕
图片字幕生成模型结合了近年来计算机视觉和机器翻译方面的进步,通过使用神经网络来生成现实图片的字幕。对于一个给定的输入...
-
处理缺失数据
许多教学中的数据和现实世界中的数据的区别在于,现实世界的数据很少干净且均匀分布的。特别是在许多有趣的数据集中,有着大...
-
Pandas中的运算
NumPy的重要特性之一是能够执行快速的元素级运算,既有基本的算术(加减乘除等),也有更为复杂的运算(三角函数、指数和对数...
-
Pandas中的对象简介
从本质上来说,Pandas中的对象可以认为是NumPy中的结构化数组的一个增强版本,其中的行和列是以标签来标识的,而不是简单的整...


Events

Reports



-

机器智能的未来
“机器智能”,在几十年间,是一个讨论热烈又饱受质疑的话题。对机器能够“思考”和“推理”的期冀,不仅引起了人类大量的想象力,...
-

数据分析的最后一英里
数据分析的产出如果仅仅是算法模型,对数据科学家而言可能没有问题。可是如果需要把数据中获得的洞察转换成有价值的行动并...
-

评估机器学习的模型
这篇评估机器学习模型的报告是源于对这个题目需求的紧迫感。这篇报告最初是发布在Dato的机器学习博客上的六篇系列博文。我是...
-

现实世界中的主动学习
线上世界中充满了丰富多彩的计算机应用创造的财宝。我们不再写信, 而是发电子邮件;我们不会在导游手册上寻找好的餐厅,而...
-

数据驱动: 创建数据文化
数据革命正进行地如火如荼。现已有讨论数据价值和如何成为数据科学家的各种会议(如Strata + Hadoop World大会)、很多畅...