分布式表示的概念是深度学习的核心,特别是在它用于自然语言任务时。那些刚刚进入这个领域的人可能会很快将它简单理解为代表某些数据的矢量。虽然这是事实,但在更概念化的层面上去理解分布式表示会增强我们对深度学习的有效性的理解。
为了研究不同类型的表示方式,我们可以做一个简单的思考练习。假设我们有一大堆“内存单元”来存储有关形状的信息。我们可以选择用单个存储单元来表示每个单独的形状,如图1所示。
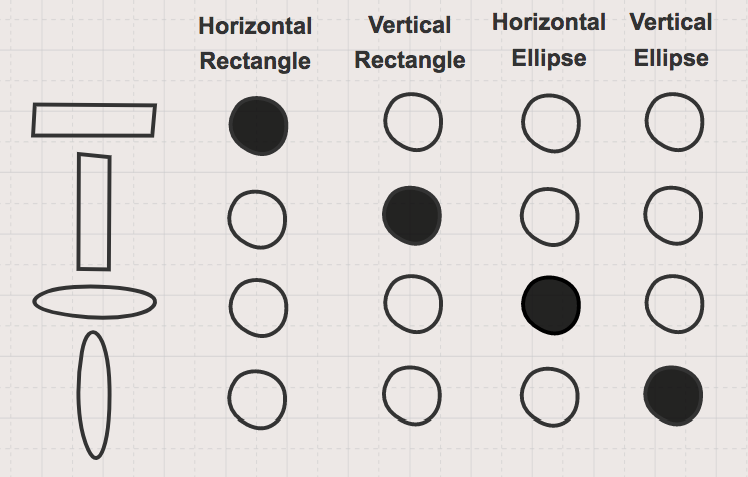
图1. 稀疏或叫本地化的非分布式的形状的表示。图片由Garrett Hoffman提供
这种被称为“稀疏”或“本地”的非分布式表示在很多方面是效率低下的。首先,随着我们观察的形状数量的增加,表示的维度将会增加。更重要的是,它没有给出关于这些形状之间如何相互关联的任何信息。而这是分布式表示真正的价值所在:它有通过概念来发现数据之间“语义相似性”的能力。
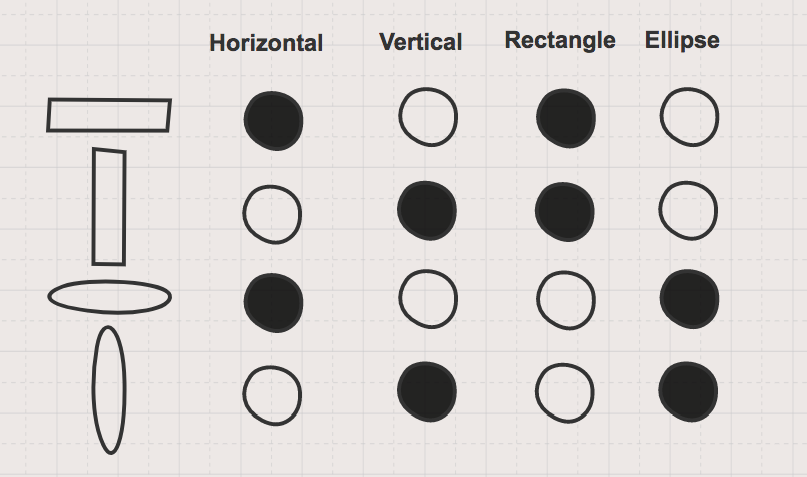
图2 对形状的分布式表示。图片由Garrett Hoffman提供
图2显示了同一组形状的分布式表示。它用与方向和形状概念相关的多个“记忆单元”表示形状的信息。“记忆单元”含有关于每个形状以及形状之间如何相互关联的信息。当通过分布式表示法(例如图3中的圆圈)来表示一个新形状时,我们不会再增加维度。而且即使我们之前没有见过圆,我们也知道关于圆的一些信息,因为它与其他形状有关。
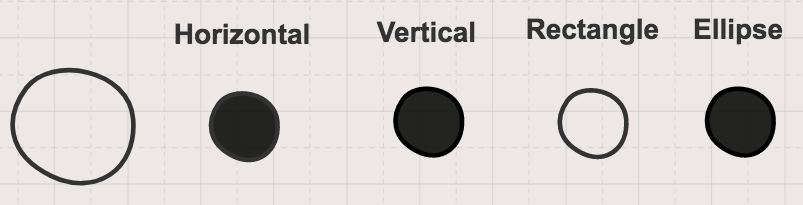
图3. 一个圆的分布式表示。这种表示法更有用,因为它为我们提供了有关这种新形状与其他形状如何相关的信息。图片由Garrett Hoffman提供
上面这个形状的例子过于简单,但它可以看成是对分布式表示的高层抽象的简介。 请注意,在上面对于形状的分布式表示的例子里,我们用了四个概念或特征(垂直、水平、矩形、椭圆)来表示。在这种情况下,我们必须事先知道这些重要和显着的特征是什么。但在很多情况下,这是一件很难或不可能的事情。正因为如此,特征工程在经典机器学习技术中才变得如此重要。找到对于数据的良好表示对于分类或聚类等任务的成功至关重要。深度学习能获得巨大成功的原因之一是神经网络具有学习丰富的分布式数据表示的能力。
为了检验这一点,我们将重新审视我们在LSTM教程中处理的问题——用StockTwits的社交媒体帖子来预测股市情绪。在这个教程中,我们构建了一个多层LSTM,以预测来自原始文本里的消息的情感。在处理消息数据时,我们创建了一个映射表来记录一个词汇到一个整数索引的关系。
词汇到整数的映射是我们数据的非分布式稀疏表示。例如,buy这个单词被映射到索引值25,long这个单词被表示为索引68。需要注意的是,这个方法和一个长度为vocab_size的“one-hot编码”(索引中有1表示该单词,而其他位置都是0)向量表示方式是等价的。这两个表示法是相互独立的,尽管在它们在语义上是相似的。两种方法里的两个词之间是没有关系信息的,两种方法里的词都仅被表示为在映射里的位置。
用于学习单词的分布式表示的规范方法是Word2Vec模型。Word2Vec的skip-gram模型的体系结构如图4所示。它用单个单词作为输入,将其传递给该单词独有的单个线性隐藏层,并使用softmax激活层预测绕着它的上下文窗口中出现的其他单词。
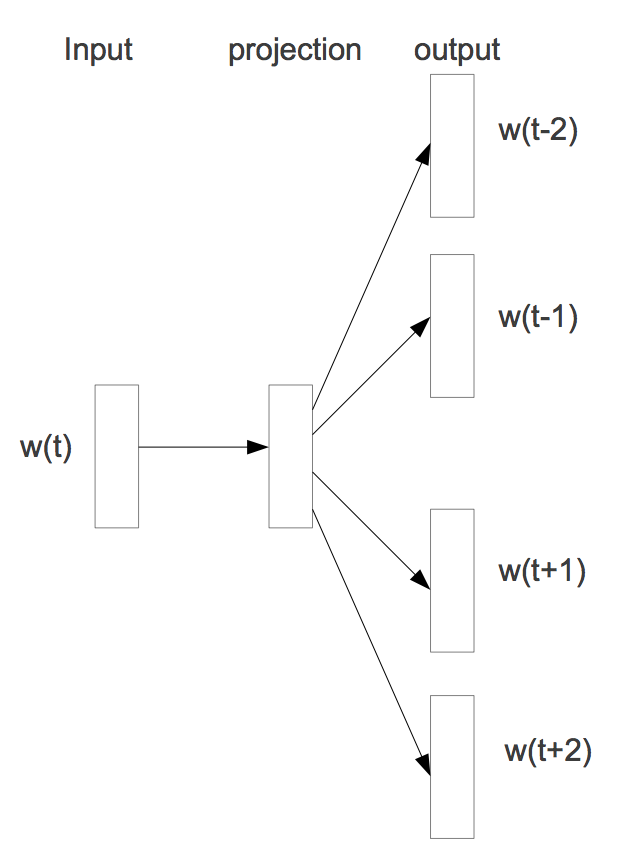
图4. 单词的分布式表示。图片来自谷歌的“Distributed Representations of Words and Phrases and their Compositionality”一文,并许可使用
Word2Vec模型使用J.R. Firth的哲学:“你可以通过一个词的上下文来理解一个词”。这一哲学可以很容易地在TensorFlow中被实现。通过学习隐藏层的权重(作为我们的分布式表示),出现在类似上下文中的单词将具有类似的表示。Word2Vec是专门设计用于从单词的上下文中学习单词的分布式表示的模型,也被称为“词嵌入”。通常是预先用Word2Vec进行训练来获得这些嵌入,然后它们再被用作其他语言任务的模型的输入。
另外一种方案是,作为特定任务的模型训练过程的一部分,可以用端到端的方式学习来获得分布式表示。这就是我们在股票市场情绪LSTM模型中学习的词嵌入。回想一下这个LSTM模型的体系结构(参见图5),其中我们将单词稀疏表示输入到一个嵌入层。
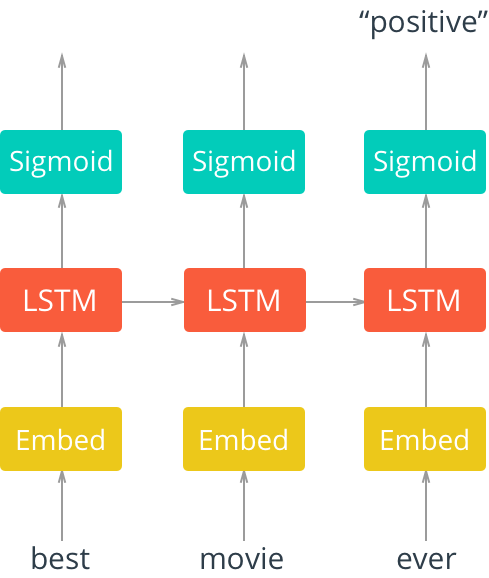
图5. 展开具有嵌入层的单层LSTM网络。图片由Udacity提供,并获许可使用
用这种范式训练,分布式表示将专门学习与任务相关的事物的表示。在我们的例子中,分布式表示应该专门学习情感词周围的语义上下文。我们可以通过提取词语嵌入并查看一些示例来检查这一点。
我们使用tSNE来可视化几个“bearish(熊市)-bullish(牛市)对”之间的关系(参见图6)。可以注意到单词对之间从左到右方向表示的情绪概念,例如bearish(熊市)-bullish(牛市),overvalued(定价过高)-undervalued(定价过低),short(短期)-long(长期)等。

图6. 可视化词嵌入。展示了我们的分布式表示所捕获的情感概念的语义关系。图片由Garrett Hoffman提供
这些表示并不完美。在理想状况下我们希望看到词对更加垂直对齐,并且我们也有一些情绪反转的词对。不过上面的结果在有限的训练中已经表现得相当不错。 我们模型的这种学习分布式表示的能力是它在预测情绪时能够达到高准确度的主要原因。
神经网络能学习到分布式数据表示的能力是深度学习能对于许多不同类型的问题非常有效的主要原因之一。这个概念的力量和美感使得表示学习成为深度学习研究中最令人兴奋和最活跃的领域之一。学习跨多种领域(例如,单词和图像、不同语言的单词)的共享表示的方法正在推进添加图像字幕和机器翻译的进步。我们可以肯定,更好地理解这些表示形式将持续作为推动人工智能发展的一个主要因素。
这篇文章是O’Reilly和TensorFlow的合作。 请参阅我们的编辑独立声明。