数字营销是指在数字平台上推广服务和产品。广告技术(通常简写为“ad tech”)是指供应商、品牌及其代理机构使用数字技术来定位潜在客户,提供个性化信息和产品,并分析线上花费带来的效果。例如,赞助的故事在Facebook新闻传播里的传播;在Instagram里的故事量;在YouTube的视频内容开始前播放的广告;由Outbrain支持的美国有线电视新闻网文章末尾的建议链接,所有这些都是实际使用广告技术的案例。
在过去的一年里,深度学习在数字营销和广告技术中得到了显著地应用。
在这篇文章中,我们将深入探讨一个流行的应用场景的一部分:挖掘网络名人认可的商品。在此过程中,我们将能了解深度学习架构的相对价值,进行实验,理解数据量大小的影响,以及在缺乏足够数据时如何增强数据等内容。
应用场景概述
在本文中,我们将看到如何建立一个深度学习分类器,该分类器可以根据带有商标的图片来预测该商品所对应的公司。本节概述了可以使用此模型的场景。
名人会认可一些产品。 通常,他们会在社交媒体上发布图片来炫耀他们认可的品牌。典型帖子会包含一张图片,其中有名人自己和他们写的一些文字。相对应的,品牌的拥有者也渴望了解这些帖子的里他们品牌的展现,并向可能受到影响的潜在客户展示它们。
因此,这一广告技术应用的工作流程如下:将大量的帖子输入处理程序以找出名人、品牌和文字内容。然后,对于每个潜在客户,机器学习模型会根据时间、地点、消息、品牌以及客户的偏好品牌和其他内容生成非常独特的广告。另外一个模型则进行目标客户群的检测。随后进行目标广告的发送。
图1显示了这一工作流程:
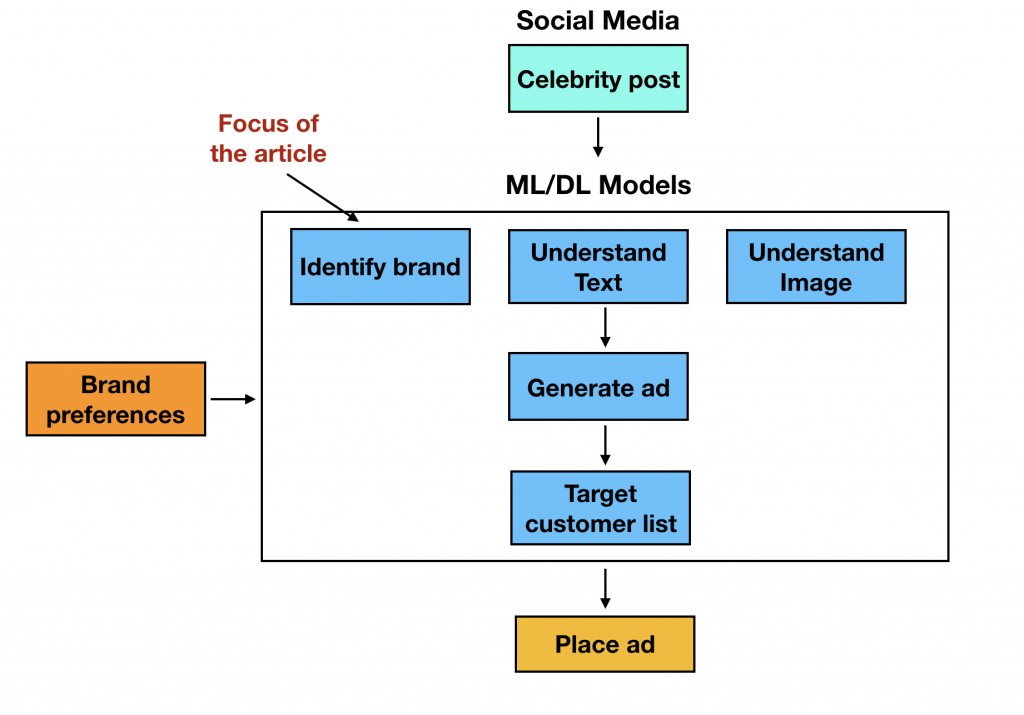
图1 名人品牌认可机器人的工作流程。图片由Tuhin Sharma提供
如你所见,该系统由多个机器学习模型组成。
考虑一下上面所说的图像。这些照片可以是在任何情况下拍摄的。因此首要目标就是确定照片中的物体和名人。这可以通过物体检测模型完成。然后,下一步是识别品牌(如果有的话)。而识别品牌最简单的方法就是通过识别它的商标。
在本文中,我们将研究如何构建一个深度学习模型来通过图像中的商标识别品牌。 后续的文章将讨论构建机器人的其他部分(物体检测、文本生成等)。
问题定义
本文中要解决的问题是:给定一张图片,通过标识图片里的商标来预测图片对应的公司(品牌)。
数据
要构建机器学习模型,获取高质量数据集是必须的。在现实业务中,数据科学家会与品牌经理和代理商合作来获得所有可能的商标。
为了本文的目的,我们将利用FlickrLogo数据集。该数据集有来自Flickr(一个流行的照片分享网站)的真实图片。FlickrLogo页面上有关于如何下载数据的说明。如果你想使用本文中的代码构建自己的模型,请自行下载数据。
模型
从商标标识别品牌是一个经典的计算机视觉问题。在过去的几年中,深度学习已成为解决计算机视觉问题的最新技术。因此我们将为我们的场景构建深度学习模型。
软件
在之前的文章中,我们谈到了Apache MXNet的优点。我们还谈到了Gluon这一基于MXNet的更简单的接口。两者都非常强大,并允许深度学习工程师快速尝试各种模型架构。
现在让我们来看看代码。
用到的库
我们首先导入构建模型所需的库:
import mxnet as mx
import cv2
from pathlib import Path
import os
from time import time
import shutil
import matplotlib.pyplot as plt
%matplotlib inline
下载数据
我们使用FlickrLogos数据集里的FlickrLogos-32数据集。变量<flickrlogos-url>是这个数据集的URL。
%%capture
!wget -nc <flickrlogos-url> # Replace with the URL to the dataset
!unzip -n ./FlickrLogos-32_dataset_v2.zip
数据准备
接着是创建下述的数据集:
1.Train (训练数据集)
2.Validation (验证数据集)
3.Test (测试数据集)
FlickrLogos数据已经分好了训练、验证和测试数据集。下面是数据里图片的信息。
- 训练数据集包括32个类别,每个类别有10张图片。
- 验证数据集里有3960张图片,其中3000张没有包含商标。
- 测试数据有3960张图片。
所有的训练数据图片都包含有商标,但有些验证和测试数据里的图片没有包含商标。我们是希望构建一个有比较好泛化能力的模型。即我们的模型可以准确地预测它没有见过的图片(验证和测试的图片)
为了让我们的训练更快速、准确,我们将把50%的没有商标的图片从验证数据集移到训练数据集。这样我们制作出大小为1820的训练数据集(在从验证数据集添加1500个无商标图像之后),并将验证数据集减少到2460张(在移出1500个无商标图像之后)。在现实生活中,我们应该尝试使用不同的模型架构来选择一个在实际验证和测试数据集上表现良好的模型架构。
下一步,我们定义存储数据的目录。
data_directory = “./FlickrLogos-v2/”
现在定义训练、测试和验证数据列表的路径。对于验证目录,我们定义两个路径:一个存放包含商标的图片,另外一个用于没有商标的图片。
train_logos_list_filename = data_directory+”trainset.relpaths.txt”
val_logos_list_filename = data_directory+”valset-logosonly.relpaths.txt”
val_nonlogos_list_filename = data_directory+”valset-nologos.relpaths.txt”
test_list_filename = data_directory+”testset.relpaths.txt”
让我们从上面定义的列表里面读入训练、测试和验证(带有商标和无商标的)数据文件名。
从FlickrLogo数据集读入的列表已经被按照训练、测试和验证(包含和未包含商标)进行了分类。
# List of train images
with open(train_logos_list_filename) as f:
train_logos_filename = f.read().splitlines()
# List of validation images without logos
with open(val_nonlogos_list_filename) as f:
val_nonlogos_filename = f.read().splitlines()
# List of validation images with logos
with open(val_logos_list_filename) as f:
val_logos_filename = f.read().splitlines()
# List of test images
with open(test_list_filename) as f:
test_filenames = f.read().splitlines()
现在让我们把一些没有商标的验证图片移动到训练集里面去。这样就让训练数据里包含了原来所有的图片,外加上来自验证数据里50%的没有商标的图片。而验证数据集现在只包含原有的所有带有商标的图片和剩下50%没有商标的图片。
train_filenames = train_logos_filename + val_nonlogos_filename[0:int(len(val_nonlogos_filename)/2)]
val_filenames = val_logos_filename + val_nonlogos_filename[int(len(val_nonlogos_filename)/2):]
为了验证我们的数据准备结果是对的,让我们打印训练、测试和验证数据集里的图片数量。
print(“Number of Training Images : “,len(train_filenames))
print(“Number of Validation Images : “,len(val_filenames))
print(“Number of Testing Images : “,len(test_filenames))
数据准备过程的下一步是设置一种目录结构来让模型的训练过程更容易一些。
我们需要目录的结构和图2里的类似。
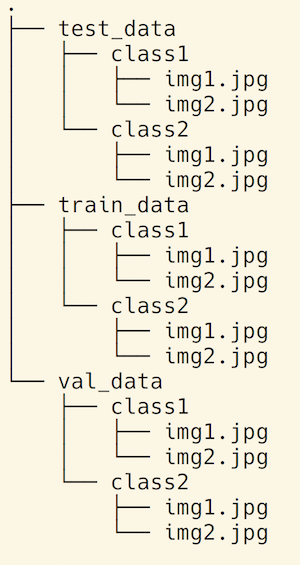
图2 数据的目录结构。图片由Tuhin Sharma提供
下面这个函数能帮助我们创建这个目录结构。
def prepare_datesets(base_directory,filenames,dest_folder_name):
for filename in filenames:
image_src_path = base_directory+filename
image_dest_path = image_src_path.replace(‘classes/jpg’,dest_folder_name)
dest_directory_path = Path(os.path.dirname(image_dest_path))
dest_directory_path.mkdir(parents=True,exist_ok=True)
shutil.copy2(image_src_path, image_dest_path)
使用这个函数来创建训练、验证和测试目录,并把图片按照它们的相应的类别放到目录里面。
prepare_datesets(base_directory=data_directory,filenames=train_filenames,dest_folder_name=’train_data’)
prepare_datesets(base_directory=data_directory,filenames=val_filenames,dest_folder_name=’val_data’)
prepare_datesets(base_directory=data_directory,filenames=test_filenames,dest_folder_name=’test_data’)
接下来是定义模型所用的超参数。
我们将会有33个类别(32种商标和1个无商标)。这个数据量并不大,所以我们将只会使用一个GPU。我们将会训练20个周期,并使用40作为训练批次的大小。
batch_size = 40
num_classes = 33
num_epochs = 20
num_gpu = 1
ctx = [mx.gpu(i) for i in range(num_gpu)]
数据预处理
在图片被导入后,我们需要确保图片的尺寸是一致的。我们会把图片重缩放成224*224像素大小。
我们有1820张训练图片,但并不算很多。有没有一个好的办法来获得更多的数据?确实是有的。一张图片在被翻转后依然是表示相同的事物,至少商标还是一样的。被随机剪裁的商标还依然是同一个商标。
因此,我们没有必要为训练来找更多的图片。而是把现有的图片通过翻转和剪切进行一定的变形来获得更多的数据。这同时这还能帮助让模型更加鲁棒。
让我们把50%的训练数据上下翻转,并把它们剪切成224*224像素大小。
train_augs = [
mx.image.HorizontalFlipAug(.5),
mx.image.RandomCropAug((224,224))
]
对于验证和测试数据,让我们按中心点剪切图片成224*224像素大小。现在所有的训练、测试和验证数据集都是224*224像素大了。
val_test_augs = [
mx.image.CenterCropAug((224,224))
]
为了实现对于图片的转换,我们定义了transform函数。这个函数按照输入的数据和增强的类型,对数据进行变换,以更新数据集。
def transform(data, label, augs):
data = data.astype(‘float32’)
for aug in augs:
data = aug(data)
# from (H x W x c) to (c x H x W)
data = mx.nd.transpose(data, (2,0,1))
return data, mx.nd.array([label]).asscalar().astype(‘float32’)
Gluon库有一个工具函数可以从文件里导入图片:mx.gluon.data.vision.ImageFolderDataset。这个函数需要数据按照图2所示的目录结构来存放。
这个函数接收如下的参数:
- 数据存储的根目录路径
- 一个是否需要把图片转换成灰度图或是彩色图(彩色是默认选项)的标记
- 一个函数来接收数据(图片)和它的标签,并将图片转换。
下面的代码展示了在导入数据后如何对其进行转换:
train_imgs = mx.gluon.data.vision.ImageFolderDataset(
data_directory+’train_data’,
transform=lambda X, y: transform(X, y, train_augs))
相同的,对于验证和测试数据集,在导入后也会进行相应的转换。
val_imgs = mx.gluon.data.vision.ImageFolderDataset(
data_directory+’val_data’,
transform=lambda X, y: transform(X, y, val_test_augs))
test_imgs = mx.gluon.data.vision.ImageFolderDataset(
data_directory+’test_data’,
transform=lambda X, y: transform(X, y, val_test_augs))
DataLoader是一个内建的工具函数来从数据集里导入数据,并返回迷你批次的数据。在上述步骤里,我们已经定义了训练、验证和测试数据集( train_imgs、val_imgs 、test_imgs相应的)。
num_workers属性让我们可以指定为数据预处理所需的多进程工作器的个数。
train_data = mx.gluon.data.DataLoader(train_imgs, batch_size,num_workers=1, shuffle=True)
val_data = mx.gluon.data.DataLoader(val_imgs, batch_size, num_workers=1)
test_data = mx.gluon.data.DataLoader(test_imgs, batch_size, num_workers=1)
现在数据已经导入了,来让我们看一看吧。让我们写一个叫show_images的工具函数来以网格形式显示图片。
def show_images(imgs, nrows, ncols, figsize=None):
“””plot a grid of images”””
figsize = (ncols, nrows)
_, figs = plt.subplots(nrows, ncols, figsize=figsize)
for i in range(nrows):
for j in range(ncols):
figs[i][j].imshow(imgs[i*ncols+j].asnumpy())
figs[i][j].axes.get_xaxis().set_visible(False)
figs[i][j].axes.get_yaxis().set_visible(False)
plt.show()
现在,用4行8列的形式来展示前32张图片。
for X, _ in train_data:
# from (B x c x H x W) to (Bx H x W x c)
X = X.transpose((0,2,3,1)).clip(0,255)/255
show_images(X, 4, 8)
break

图3 进行变形后的图片的网格化展示。图片由Tuhin Sharma提供
上面代码的运行结果如图3所示。一些图片看起来是含有商标的,不过也经常被切掉了一部分。
用于训练的工具函数
本节内,我们会定义如下一些函数:
- 在当前处理的批次里获取数据
- 评估模型的准确度
- 训练模型
- 给定URL,获取图片数据
- 对给定的图片,预测图片的标签
第一个函数_get_batch会返回指定批次的数据和标签。
def _get_batch(batch, ctx):
“””return data and label on ctx”””
data, label = batch
return (mx.gluon.utils.split_and_load(data, ctx),
mx.gluon.utils.split_and_load(label, ctx),
data.shape[0])
函数evaluate_accuracy会返回模型的分类准确度。针对本文的目的,我们这里选择了一个简单的准确度指标。在实际项目里,准确度指标需要根据应用的需求来设定。
def evaluate_accuracy(data_iterator, net, ctx):
acc = mx.nd.array([0])
n = 0.
for batch in data_iterator:
data, label, batch_size = _get_batch(batch, ctx)
for X, y in zip(data, label):
acc += mx.nd.sum(net(X).argmax(axis=1)==y).copyto(mx.cpu())
n += y.size
acc.wait_to_read()
return acc.asscalar() / n
下一个定义的函数是train函数。这是到目前为止我们要创建的最大的函数。
根据给出的模型、训练、测试和验证数据集,模型被按照指定的周期数训练。在之前的一篇文章里,我们对这个函数如何运作进行了更详细的介绍。
一旦在验证数据集上获得了最佳的准确度,这个模型在此检查点的结果会被存下来。在每个周期里,在训练、验证和测试数据集上的准确度都会被打印出来。
def train(net, ctx, train_data, val_data, test_data, batch_size, num_epochs, model_prefix, hybridize=False, learning_rate=0.01, wd=0.001):
net.collect_params().reset_ctx(ctx)
if hybridize == True:
net.hybridize()
loss = mx.gluon.loss.SoftmaxCrossEntropyLoss()
trainer = mx.gluon.Trainer(net.collect_params(), ‘sgd’, {
‘learning_rate’: learning_rate, ‘wd’: wd})
best_epoch = -1
best_acc = 0.0
if isinstance(ctx, mx.Context):
ctx = [ctx]
for epoch in range(num_epochs):
train_loss, train_acc, n = 0.0, 0.0, 0.0
start = time()
for i, batch in enumerate(train_data):
data, label, batch_size = _get_batch(batch, ctx)
losses = []
with mx.autograd.record():
outputs = [net(X) for X in data]
losses = [loss(yhat, y) for yhat, y in zip(outputs, label)]
for l in losses:
l.backward()
train_loss += sum([l.sum().asscalar() for l in losses])
trainer.step(batch_size)
n += batch_size
train_acc = evaluate_accuracy(train_data, net, ctx)
val_acc = evaluate_accuracy(val_data, net, ctx)
test_acc = evaluate_accuracy(test_data, net, ctx)
print(“Epoch %d. Loss: %.3f, Train acc %.2f, Val acc %.2f, Test acc %.2f, Time %.1f sec” % (
epoch, train_loss/n, train_acc, val_acc, test_acc, time() – start
))
if val_acc > best_acc:
best_acc = val_acc
if best_epoch!=-1:
print(‘Deleting previous checkpoint…’)
os.remove(model_prefix+’-%d.params’%(best_epoch))
best_epoch = epoch
print(‘Best validation accuracy found. Checkpointing…’)
net.collect_params().save(model_prefix+’-%d.params’%(epoch))
函数get_image会根据给定的URL返回一个图片。这个函数可以用来测试模型的准确度。
def get_image(url, show=False):
# download and show the image
fname = mx.test_utils.download(url)
img = cv2.cvtColor(cv2.imread(fname), cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
plt.imshow(img)
return fname
最后一个工具函数是classify_logo。给定图片和模型,这个函数将会返回此图片的分类(在我们的场景里就是品牌的名字)和此分类相应的概率。
def classify_logo(net, url):
fname = get_image(url)
with open(fname, ‘rb’) as f:
img = mx.image.imdecode(f.read())
data, _ = transform(img, -1, val_test_augs)
data = data.expand_dims(axis=0)
out = net(data.as_in_context(ctx[0]))
out = mx.nd.SoftmaxActivation(out)
pred = int(mx.nd.argmax(out, axis=1).asscalar())
prob = out[0][pred].asscalar()
label = train_imgs.synsets
return ‘With prob=%f, %s’%(prob, label[pred])
模型
理解模型的架构是非常重要的。在我们之前的那篇文章里,我们构建了一个多层感知机(MLP)。此架构如图4所示。
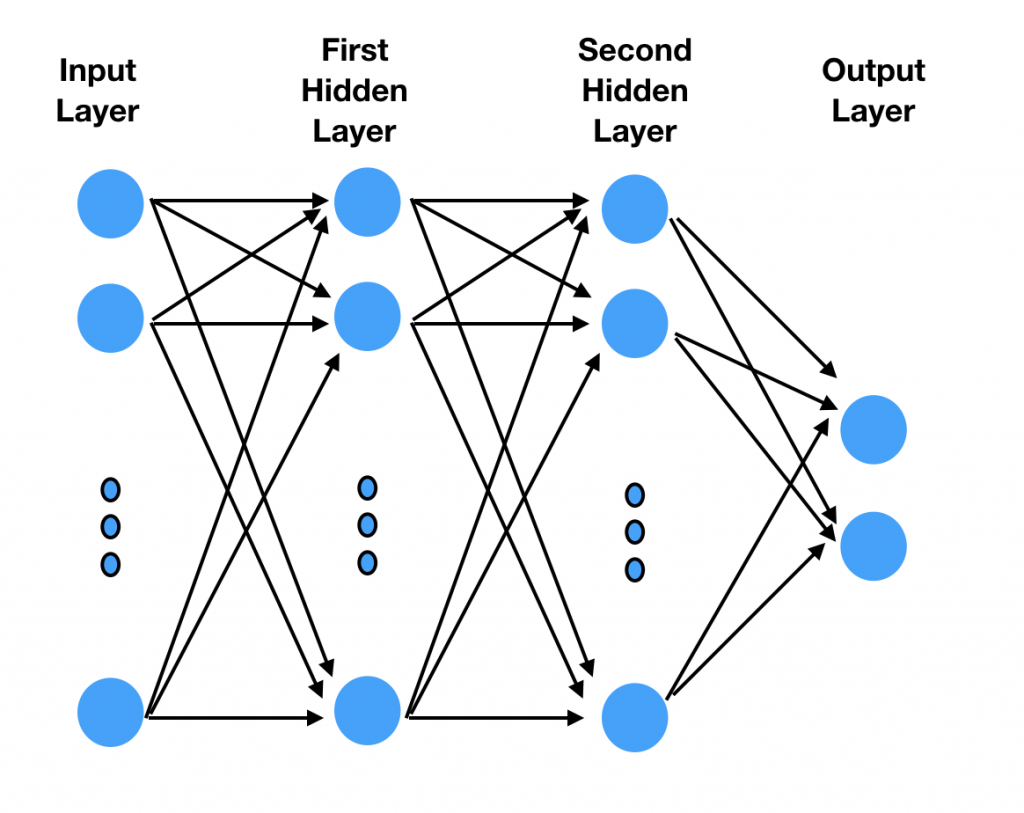
图4 多层感知机。图片由Tuhin Sharma提供
此MLP模型的输入层应该是怎么样的?我的数据图片的尺寸是224 * 224像素。
构建输入层的最常见的方法就是把图片打平,构建一个50176个(224 * 224)神经元的输入层。这就形成了一个如图5所示的简单的数据流。
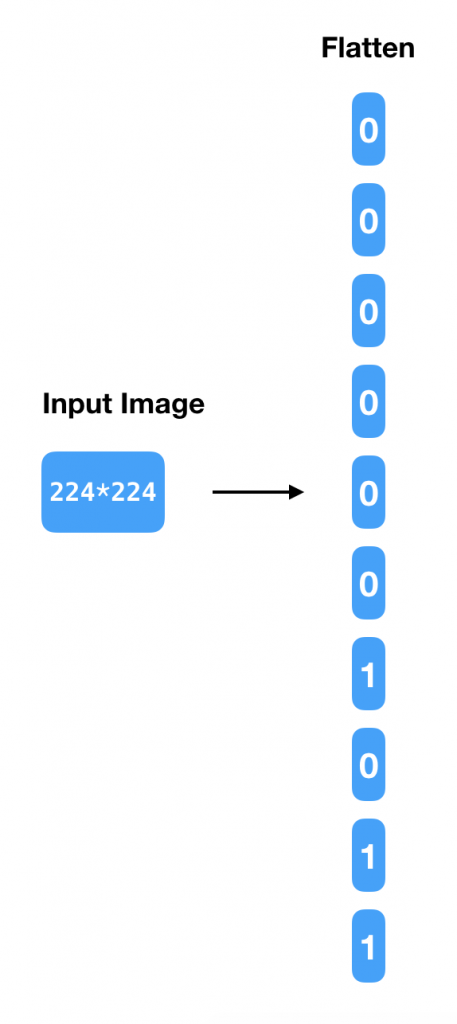
图5 扁平化输入。图片由Tuhin Sharma提供
但是当进行这样的扁平化处理后,图像数据里的很多空间信息被丢失了。同时另外一个挑战是相应的权重数量。如果第一个隐藏层有30个神经元,那么这个模型的参数将会有50176 * 30再加上30个偏置量。因此,这看来不像是一个好的为图像建模的方法。
现在让我们来讨论一下一个更合适的架构:用于图片分类的卷积神经网络(CNN)。
卷积神经网络(CNN)
CNN和MLP类似,因为它也是构建神经网络并为神经元学习权重。CNN和MLP的关键的区别是输入数据是图片。CNN允许我们在架构里充分利用图片的特性。
CNN有一些卷积层。这个词汇“卷积”是来自图像处理领域,如图6所述。它工作于一个较小的窗口,叫做“感知域”,而不是处理来自前一层的所有输入。这种机制就可以让模型学习局部的特征。
每个卷积层用一个小矩阵(叫卷积核)在进入本层的图像上面的一部分上移动。卷积会对卷积矩阵内的每个像素进行修改,此运算可以帮助识别边缘。图6的左边展示了一个图片,中间是一个3×3的卷积核,而运用此卷积核对左边图片的左上角像素计算的结果显示在右边图里。我们还能定义多个卷积核,来表示不同的特征图。
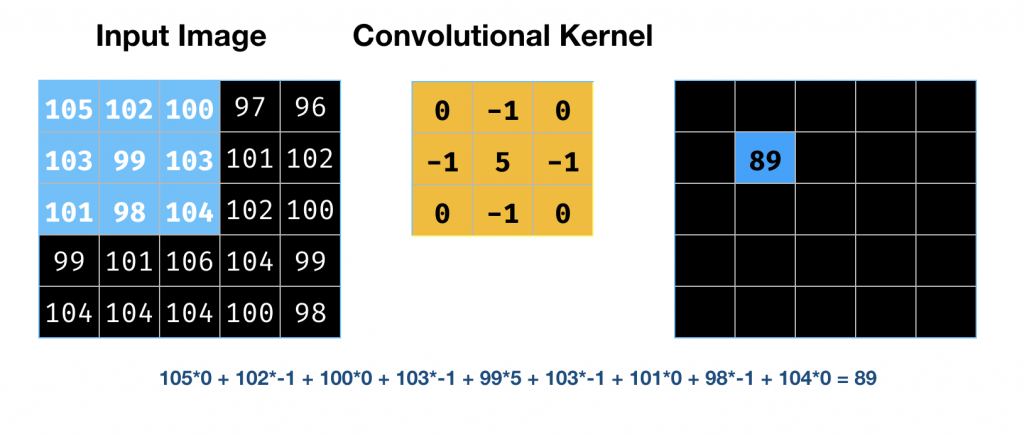
图6 卷积层。图片由Tuhin Sharma提供
在图6的例子里,输入的图片的尺寸是5×5,而卷积核的尺寸是3×3。卷积计算是两个矩阵的元素与元素的乘积之和。例子里卷积的输出尺寸也是5×5。
为了理解这些,我们需要理解卷积层里的两个重要参数:步长(stride)和填充方法(padding)。
步长控制卷积核(过滤器)如何在图片上移动。
图7表明了卷积核从第一个像素到第二个像素的移动过程。
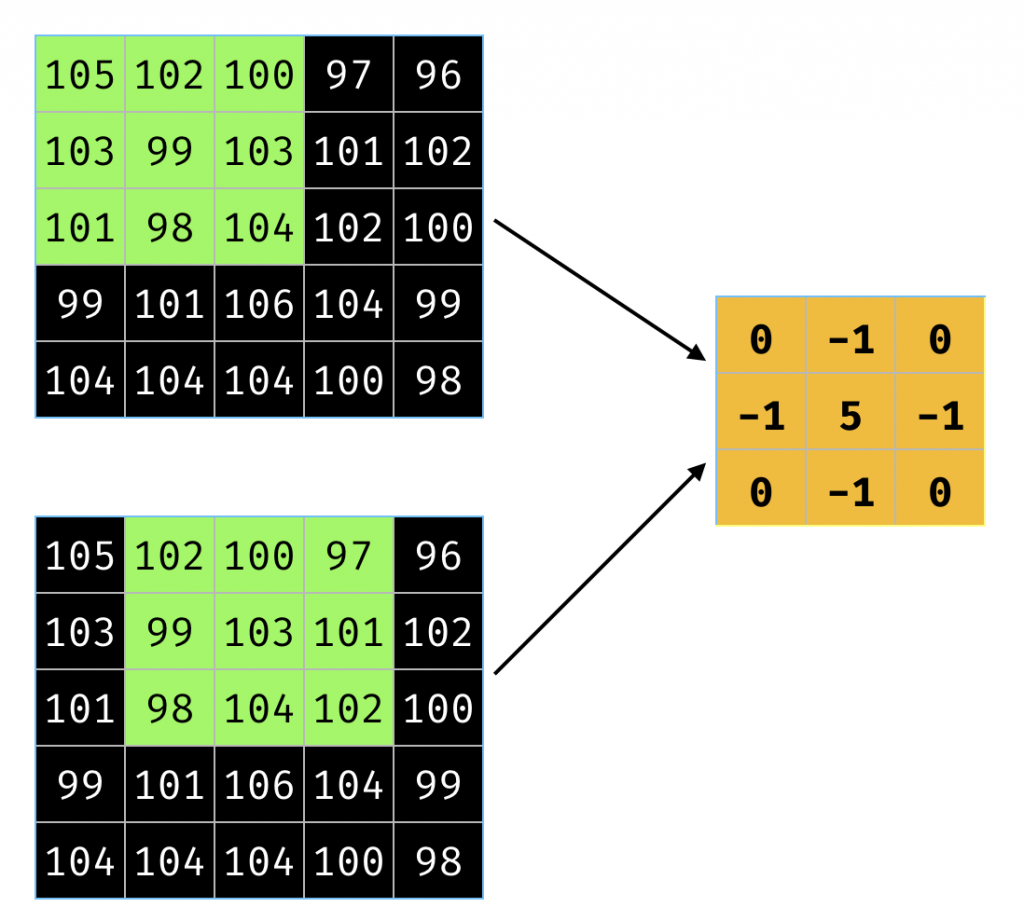
图7 卷积核的移动。图片由Tuhin Sharma提供
在图7里,步长是1。
当对一个5×5的图片进行3×3的卷积计算后,我们将得到一个3×3的图片。针对这一情况,我们会在图片的边缘进行填充。现在这个5×5的图片被0所围绕,如图8所示。
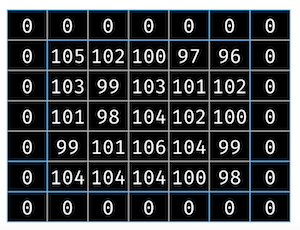
图8 用0填充边缘。图片由Tuhin Sharma提供
这样,当我们用3×3卷积核计算时,将会获得一个5×5的输出。
因此对于图6所示的计算,它的步长是1,且填充的尺寸也是1。
CNN比相应的MLP能极大地减少权重的数量。假设我们使用30个卷积核,每个是3×3。每个卷积核的参数是3×3=9,外加1个偏置量。这样每个卷积核有10个权重,总共30个卷积核就是300个权重。而在前面的章节里,MLP则是有150000个权重。
下一层一般典型地是一个子抽样层。一旦我们识别了特征,这一子抽样层会简化这个信息。一个常用的方法是最大池化。它从卷积层输出的局部区域输出最大值(见图9)。这一层在保留了每个局部区域的最大激活特征的同时,降低了输出的尺寸。
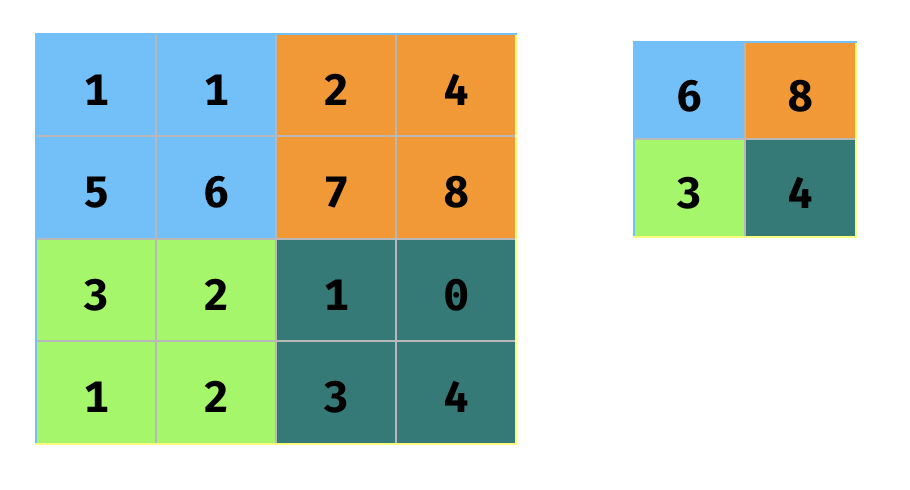
图9 最大池化。图片由Tuhin Sharma提供
可以看到最大池化在保留了每个局部区域的最大激活特征的同时,降低了输出的尺寸。
想了解关于CNN的更多的信息,一个好的资源是这本在线图书《神经网络和深度学习》。另外一个好的资源是斯坦福大学的CNN课程。
现在我们已经对什么是CNN有了基本的了解。为了这里的问题,让我们用gluon来实现它。
第一步是定义这个架构:
cnn_net = mx.gluon.nn.Sequential()
with cnn_net.name_scope():
# First convolutional layer
cnn_net.add(mx.gluon.nn.Conv2D(channels=96, kernel_size=11, strides=(4,4), activation=’relu’))
cnn_net.add(mx.gluon.nn.MaxPool2D(pool_size=3, strides=2))
# Second convolutional layer
cnn_net.add(mx.gluon.nn.Conv2D(channels=192, kernel_size=5, activation=’relu’))
cnn_net.add(mx.gluon.nn.MaxPool2D(pool_size=3, strides=(2,2)))
# Flatten and apply fullly connected layers
cnn_net.add(mx.gluon.nn.Flatten())
cnn_net.add(mx.gluon.nn.Dense(4096, activation=”relu”))
cnn_net.add(mx.gluon.nn.Dense(num_classes))
在模型架构被定义好之后,让我们初始化网络里的权重。我们将使用Xavier初始器。
cnn_net.collect_params().initialize(mx.init.Xavier(magnitude=2.24), ctx=ctx)
权重初始化完后,我们可以训练模型了。我们会调用之前定义的相同的train函数,并传给它所需的参数。
train(cnn_net, ctx, train_data, val_data, test_data, batch_size, num_epochs,model_prefix=’cnn’)
Epoch 0. Loss: 53.771, Train acc 0.77, Val acc 0.58, Test acc 0.72, Time 224.9 sec
Best validation accuracy found. Checkpointing…
Epoch 1. Loss: 3.417, Train acc 0.80, Val acc 0.60, Test acc 0.73, Time 222.7 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 2. Loss: 3.333, Train acc 0.81, Val acc 0.60, Test acc 0.74, Time 222.5 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 3. Loss: 3.227, Train acc 0.82, Val acc 0.61, Test acc 0.75, Time 222.4 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 4. Loss: 3.079, Train acc 0.82, Val acc 0.61, Test acc 0.75, Time 222.0 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 5. Loss: 2.850, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.7 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 6. Loss: 2.488, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.1 sec
Epoch 7. Loss: 1.943, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 8. Loss: 1.395, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 223.6 sec
Epoch 9. Loss: 1.146, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.5 sec
Epoch 10. Loss: 1.089, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.5 sec
Epoch 11. Loss: 1.078, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.7 sec
Epoch 12. Loss: 1.078, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.1 sec
Epoch 13. Loss: 1.075, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 14. Loss: 1.076, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 15. Loss: 1.076, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.4 sec
Epoch 16. Loss: 1.075, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 17. Loss: 1.074, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.8 sec
Epoch 18. Loss: 1.074, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.8 sec
Epoch 19. Loss: 1.073, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.9 sec
我们让模型运行20个周期。典型的情况是,我们会训练非常多的周期,并选择验证准确度最高的那个模型。在上面运行了20个周期后,我们可以在日志里看到验证准确度最高的是在周期5。在此周期之后,模型看起来并没有学到更多。有可能网络已经饱和,学习速度变慢了。我们下一节里会试一个更好的方法,但还是先让我们看看现在这个模型的表现如何。
让我们把最佳验证准确度的模型参数导入,然后分配给我们的模型:
cnn_net.collect_params().load(‘cnn-%d.params’%(5),ctx)
现在让我们看看这个模型在新数据上的表现。我们会从网上获取一个容易识别的图片(见图10),并看看模型是否能准确地识别。
img_url = “http://sophieswift.com/wp-content/uploads/2017/09/pleasing-ideas-bmw-cake-and-satisfying-some-bmw-themed-cakes-crustncakes-delicious-cakes-128×128.jpg”
classify_logo(cnn_net, img_url)
‘With prob=0.081522, no-logo’

图10 BMW的商标。图片由Tuhin Sharma提供
模型的预测结果很糟糕。它认为这个图片里没有包含商标的概率是8%。预测的结果是错的,且概率非常低。
让我们再试一张图片(见图11)来看看准确率是否有改善。
img_url = “https://dtgxwmigmg3gc.cloudfront.net/files/59cdcd6f52ba0b36b5024500-icon-256×256.png”
classify_logo(cnn_net, img_url)
‘With prob=0.075301, no-logo’

图11 Foster的商标。图片由Tuhin Sharma提供
又一次,模型的预测结果是错的,且概率很低。
我们没有太多的数据,而如上所见,模型训练得已经饱和。我们可以继续试验更多的模型架构,但是我们没法克服小数据集的问题,因为可训练的参数远远大于训练图片的数量。那我们如何克服这个问题?在没有太多数据的情况下不能使用深度学习吗?
对此的答案就是迁移学习。下面接着讨论。
迁移学习
想想这个比喻。你想学一门新的外语,怎么进行哪?
例如,你可以进行一个对话。导师:你好吗?你:我很好,你怎么样?
你也能试着对新的外语做一样的事。
因为你的英语很熟练,你可以不用从零开始学一门新的语言(即使看起来你是这样做的)。你对一门语言已经有了心智图,你可以试着在新的语言里找到相应的词汇。因此在新的语言里,你的词汇表可能依然有限,但凭借你对于英语对话结构的知识,你依然能用新语言进行对话。
迁移学习的工作机制也是一样的。高准确度模型是在海量数据集上训练出来的。一个常见的数据集是ImageNet数据集。它有超过一百万张图片。全球的研究人员已经使用这个数据构建了很多不同的前沿的模型。这些模型(包括模型的架构和训练好的权重)都在网络上可以获得。
通过这些预先训练好的模型,我们将再次对于我们的问题来训练这个模型。事实上,这种情况是非常普通的。几乎总是这样的,大家首先构建的能解决计算机视觉问题的模型都是使用了一个预先训练好的模型。
在诸如我们的例子的很多场景里,如果受限于数据,这可能是所有人都能做的。
一个典型的方法是保持模型的前面层不变,只训练最后一层。如果数据量非常有限,只需要把分类层再训练就可以了。如果数据量相对充足,可以把最后的几层都再训练一下。
这是有效的,因为卷积神经网络在每个连续层学习更高层次的表示。它在许多早期阶段所做的学习在所有图像分类问题中都是共同的。
现在让我们使用一个预先训练的模型来做商标检测。
MXNet有一个模型库,里面有很多预先训练好的模型。
我们会使用一个流行的预先训练的模型,它叫resnet。这篇论文里提供了这个模型架构的很多细节内容。一个简单一些的解释可以在这篇文章里找到。
让我们先下载这个预训练过的模型:
from mxnet.gluon.model_zoo import vision as models
pretrained_net = models.resnet18_v2(pretrained=True)
因为我们的数据很少,所以我们将只训练最后的输出层。我们先随机初始化输出层的权重。
finetune_net = models.resnet18_v2(classes=num_classes)
finetune_net.features = pretrained_net.features
finetune_net.output.initialize(mx.init.Xavier(magnitude=2.24))
现在我们调用之前一样的训练函数:
train(finetune_net, ctx, train_data, val_data, test_data, batch_size, num_epochs,model_prefix=’ft’,hybridize = True)
Epoch 0. Loss: 1.107, Train acc 0.83, Val acc 0.62, Test acc 0.76, Time 246.1 sec
Best validation accuracy found. Checkpointing…
Epoch 1. Loss: 0.811, Train acc 0.85, Val acc 0.62, Test acc 0.77, Time 243.7 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 2. Loss: 0.722, Train acc 0.86, Val acc 0.64, Test acc 0.78, Time 245.3 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 3. Loss: 0.660, Train acc 0.87, Val acc 0.66, Test acc 0.79, Time 243.4 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 4. Loss: 0.541, Train acc 0.88, Val acc 0.67, Test acc 0.80, Time 244.5 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 5. Loss: 0.528, Train acc 0.89, Val acc 0.68, Test acc 0.80, Time 243.4 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 6. Loss: 0.490, Train acc 0.90, Val acc 0.68, Test acc 0.81, Time 243.2 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 7. Loss: 0.453, Train acc 0.91, Val acc 0.71, Test acc 0.82, Time 243.6 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 8. Loss: 0.435, Train acc 0.92, Val acc 0.70, Test acc 0.82, Time 245.6 sec
Epoch 9. Loss: 0.413, Train acc 0.92, Val acc 0.72, Test acc 0.82, Time 247.7 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 10. Loss: 0.392, Train acc 0.92, Val acc 0.72, Test acc 0.83, Time 245.3 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 11. Loss: 0.377, Train acc 0.92, Val acc 0.72, Test acc 0.83, Time 244.5 sec
Epoch 12. Loss: 0.335, Train acc 0.93, Val acc 0.72, Test acc 0.84, Time 244.2 sec
Epoch 13. Loss: 0.321, Train acc 0.94, Val acc 0.73, Test acc 0.84, Time 245.0 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 14. Loss: 0.305, Train acc 0.93, Val acc 0.73, Test acc 0.84, Time 243.4 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 15. Loss: 0.298, Train acc 0.93, Val acc 0.73, Test acc 0.84, Time 243.9 sec
Epoch 16. Loss: 0.296, Train acc 0.94, Val acc 0.75, Test acc 0.84, Time 247.0 sec
Deleting previous checkpoint…
Best validation accuracy found. Checkpointing…
Epoch 17. Loss: 0.274, Train acc 0.94, Val acc 0.74, Test acc 0.84, Time 245.1 sec
Epoch 18. Loss: 0.292, Train acc 0.94, Val acc 0.74, Test acc 0.84, Time 243.9 sec
Epoch 19. Loss: 0.306, Train acc 0.95, Val acc 0.73, Test acc 0.84, Time 244.8 sec
现在这个模型马上就有了更好的准确度。典型的情况是,当数据比较少时,我们只训练几个周期,再选验证准确度最高的那个周期的模型。
现在,周期16有最好的验证准确度。因为训练数据有限,再继续训练的话,模型就开始出现过拟合。我们可以看到在周期16后,随着训练准确度的增加,验证准确度却开始下降了。
让我们导入周期16相应的检查点存储的参数,并用它们作为最后的模型。
# The model’s parameters are now set to the values at the 16th epoch
finetune_net.collect_params().load(‘ft-%d.params’%(16),ctx)
评估预测的结果
对于我们之前用于评估的相同的图片,让我们看看新模型的预测结果。
img_url = “http://sophieswift.com/wp-content/uploads/2017/09/pleasing-ideas-bmw-cake-and-satisfying-some-bmw-themed-cakes-crustncakes-delicious-cakes-128×128.jpg”
classify_logo(finetune_net, img_url)
‘With prob=0.983476, bmw’

图12图片由Tuhin Sharma提供
我们看到这个模型用98%的概率预测对了BMW这个商标。
现在让我们试一试另外一个之前测试的图片。
img_url = “https://dtgxwmigmg3gc.cloudfront.net/files/59cdcd6f52ba0b36b5024500-icon-256×256.png”
classify_logo(finetune_net, img_url)
‘With prob=0.498218, fosters’
尽管预测的概率并不高,比50%略低。但Foster依然是所有商标里概率最高的那个。
进一步改进这个模型
为了改进模型,我们需要改正一下我们构建训练数据集的方式。每个商标都有10张训练图。但是,为了把一些验证图像从验证集里转到训练集,我们将1500张图像作为无商标的例子移动到训练集里。这导致了显著的数据偏差,这可不是一个好方法。以下是解决此问题的一些选项:
- 给交叉熵损失赋予一定的权重。
- 在训练数据里不包含无商标的图片。从而训练一个对不包含商标的测试和验证图片预测成所有商标都有很低的概率的模型。
但请记住,即使在用迁移学习和数据增强的情况下,我们也只有320个商标图片。这对于想建立高度精确的深度学习模型而言还是太少了。
总结
在本文中,我们学习了如何使用MXNet构建图像识别模型。Gluon是进行快速原型试验的理想选择。使用杂交和符号导出,把原型转变成生产系统也非常容易。 通过使用MXNet上大量预先训练的模型,我们能够在相当快的时间内获得非常好的商标检测模型。一个很好的学习这背后的理论的资源是斯坦福大学的CS231n课程。
这篇博文是O’Reilly和Amazon的合作产物。请阅读我们的编辑独立声明。







