近年来,『异常检测』这一术语(有时也称作离群点检测)越来越多地出现在互联网和会议演示中,尽管这不是一个新的话题了。 有些领域已经使用了很长一段时间了。 目前,由于银行业务,审计,物联网(IoT)等方面的进步,异常检测已成为很多领域中相当普遍的任务。 与其他广泛应用的任务一样,异常检测可以使用多种技术和工具来解决。 因此,在考察『异常检测是什么』和『异常检测的工作机制是什么』的时候,会引起不少困扰。
本文将探讨如何使用Apache MXNet ,利用不同类型的神经网络来检测时间序列数据中的异常情况。MXNet是一种快速、可扩展的训练和推理框架,它提供了一个易于使用、简洁的机器学习API。本教程使用Python Jupyter Notebook。 到本教程结束时,您应该:
•知道什么是异常检测,以及解决这个问题的常用技术
•自己能够搭建MXNet环境
•判断不同类型的网络之间的差异,以及他们的优势和劣势
•为这样的任务加载和预处理数据
•在MXNet中构建网络体系结构
•使用MXNet训练模型并将其用于预测
本教程中使用的所有代码和数据都可以在GitHub上找到。
异常检测
在提及任何机器学习任务的概念时,我倾向于在一开始就指出,许多情况下,这一任务实际上是关于『发现模式』的。因此在这个问题里也不例外。异常检测的模型训练需要我们在训练数据中找到一种模式,然后我们可以根据这种模式来判断哪些观测点不符合这种模式。这些观测点被称为是『异常点』或者『离群点』。换句话说,我们将要寻找那些偏离正常模式的情况,这些情况是罕见的、意料之外的。
图1显示了一个人心跳异常,暗示了某种医学上的症状。
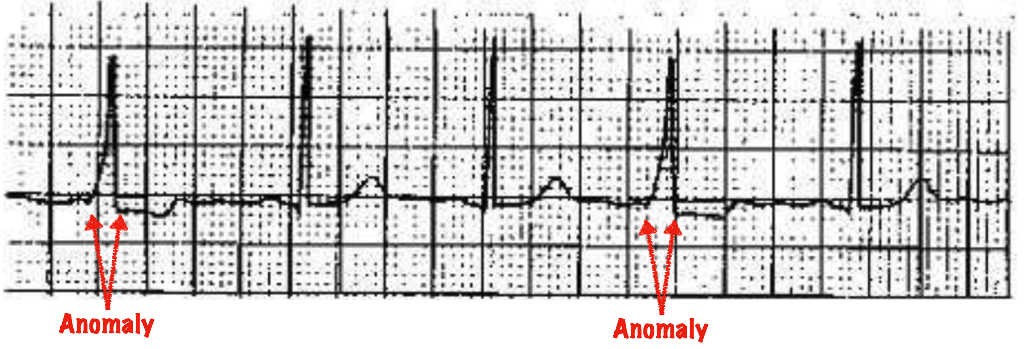
图1. Wolff-Parkinson-White综合征是一种心跳异常,您可以清楚地看到δ波如何扩大心室复杂性并缩短PR间期。 图由Mateusz Dymczyk提供
我们必须在异常检测和『新颖性检测』之间做出重要的区分。后者会把新的,以前未被发现的事件暴露出来,这些事件仍然是可以接受的和预期之内的。 例如,在某个时间点,您的信用卡账单可能会开始显示您从未购买过的婴儿用品。 这些是训练数据中未发现的新观察结果,但考虑到消费者生活的正常变化,可能是可接受的购买行为,不应将其标记为异常。
异常也可以用于多种用例:
• 预测性维护。 在工厂或任何类型的物联网环境中,您可以使用在正常执行模式下收集的数据构建模型,并使用它来预测即将发生的故障。 这意味着不会让意外的停产事故发生。
• 欺诈识别。 金融机构经常使用这种技术来捕捉到意外的消费:例如,如果您的信用卡被盗的情况下。
• 卫生保健。 比如用于医疗诊断。
• 网络安全。 你曾想过要抓住所有试图入侵你的系统的入侵者吗? 异常检测可以帮到你。
同样,如前所述,可以使用广泛的方法来解决这个问题。 一些最受欢迎的方案包括:
•卡尔曼滤波器,它使用简单的统计方法
•基于深度学习的自动编码器
当您尝试使用大多数这些算法时会出现几个问题。 例如,他们倾向于对数据做出特定的假设,有些不适用于多元数据集。
这就是为什么今天我们将使用刚才最后提到的方法展开研究,这种方法使用多层感知器和长期短期记忆(LSTM)网络两个模型。
为了简单起见,本教程只使用其中一个,其他方法可能也不错,但是神经网络的好处是他们在模拟多元问题方面很在行,适合部署到生产环境中(特别是类似于本例这种情况在使用IoT时间序列数据时更加适合)。
自编码机
我们在这里讨论的网络类型有很多名字:autoencoder; autoassociator; 还是我个人最喜欢的Diabolo。 该技术是一种用于无监督学习高效编码的人工神经网络。 简单来说,这意味着它被用来找到一种不同的方式来表示(编码)我们的输入数据。 自编码机有时也用于减少数据的尺寸。
自动编码器通过两个步骤找到Identity函数(Id:X→X)的近似值:
1.编码器步骤,将输入数据转换为中间状态
2.解码器步骤,将其转换为能够匹配输入特征大小的数据

图2.自编码机流程图,我们输入一个数字(4)的图像,将其编码为压缩格式,然后将其解码为图像格式。 图由Mateusz Dymczyk提供
用数学爱好者看得懂的方式来说,这个流程包含两个转换函数:
ϕ:X→F
ψ:F→X
通常,自动编码器通过优化输出层和输入层之间的均方误差来进行训练,其中X是输入向量, Y是输出向量, n是元素(此处为图像像素)的数量:
Y=(ψ∘ϕ)X
MSE=1n∑ni=1(Y−X)2
在我们完成了自编码机的训练之后,我们需要设置一个阈值,来判定我们是否侦测到了异常。 根据具体情况和数据,有不同的方法设置这个阈值 – 例如,根据受试者操作特性曲线(ROC)或F1分数都可以。 您设置的阈值越高,系统检测异常的时间就越长(在某些情况下会检测到更少的异常)。 在本教程中,我们将在完成训练模型之后对训练数据集进行预测,计算每个预测的误差,并找出这些误差的均值和标准差。 所有高于第三个标准偏差的样本将被标记为异常。
系统设置
在我们进入数据分析和建模之前,我们需要先安装一些工具。 我强烈建议使用某种Python环境管理系统,如Anaconda或Virtualenv。 本教程将使用后者。
1.安装Virtualenv。 在大部分系统上简单执行pip install virtualenv即可安装。
2.创建一个新的virtualenv环境,执行virtualenv oreilly-anomaly即可. 在当前目录下这会创建一个名为『oreilly-anomaly』的新文件夹。
3.通过. oreilly-anomaly/bin/activate命令激活环境。
4.通过运行pip install numpy pandas ipython jupyter ipykernel matplotlib来安装Numpy, Pandas, Jupyter Notebook, and Matplotlib。
5.安装 MXNet。
6.执行如下命令把该虚拟环境加入Jupyter Kernel中:python -m ipykernel install –user –name=oreilly-anomaly
7.运行notebook:jupyter notebook .
8.在Jupyter中,选择oreilly这一kernel: Menu → Kernel → Change kernel → oreilly-anomaly
数据集
正如介绍中所提到的,无论数据究竟带不带标签,异常检测都可以用于多种行业的数据。今天,我们将使用基于物联网的数据,这些数据可以用来进行预测性维护。 通过预测性维护,您可以使用机器数据提前预测可能发生问题的时间。 相比定期维护,它有许多优点。 在传统系统中,您必须非常了解自己的机器,才能知道需要多长时间维护一次,否则你就需要频繁地进行检查。 如果不然,整个系统就有宕机的可能性。
本数据是由东京一家创业公司LP研究所制造的硬件传感器收集的。 这次使用的传感器可以读取多达21个不同的值,包括X,Y和Z维度上的线性加速度(速度在单一方向上的变化率)。 现在为了简单起见(也为了方便可视化),我们将只使用一个特征:X方向上的线性加速度。在现实情况中,您可能会想要使用更多方向上的数据,特别是在使用神经网络时,因为它们会自动进行特征工程。
图3显示了该特征的样本数据。
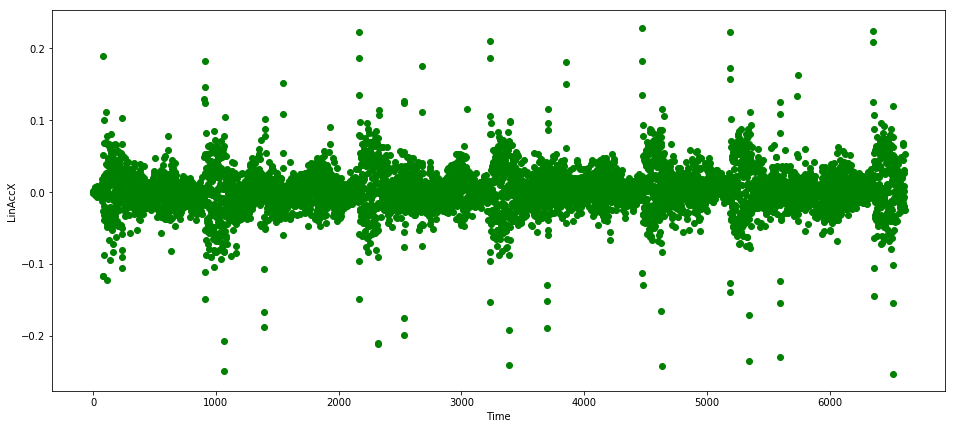
图3.关于设备X方向上线性加速度的IoT数据。图片由Mateusz Dymczyk提供
可以看到,这些数据具有周期性,特征尺度也比较好 —— 然而并不总是如此。 要注意到,尖峰偶尔出现,它们属于正常情况,而不会被归类为异常。我们需要确保我们的模型足够聪明来正确地处理这些样本点。
前馈网络
在处理机器学习问题时,从一个简单的解决方案开始迭代总是一个好主意。 否则,你可能从一开始就迷失在复杂性中。
出于这个原因,我们首先将使用最简单的神经网络之一 – 多层感知器(MLP)来实现我们的自编码机。 一个MLP是一种前馈神经网络,意思是一个没有循环迭代,所有的连接都向前(与我们将在下一节中使用的递归神经网络是相反的)。 MLP是一个简单的网络,至少有三层:输入,输出和至少一个隐藏层。 前馈自编码器是一种特殊类型的MLP,其中输入层中的神经元数量与输出层中的神经元数量相同。 图4是一个简单的例子。
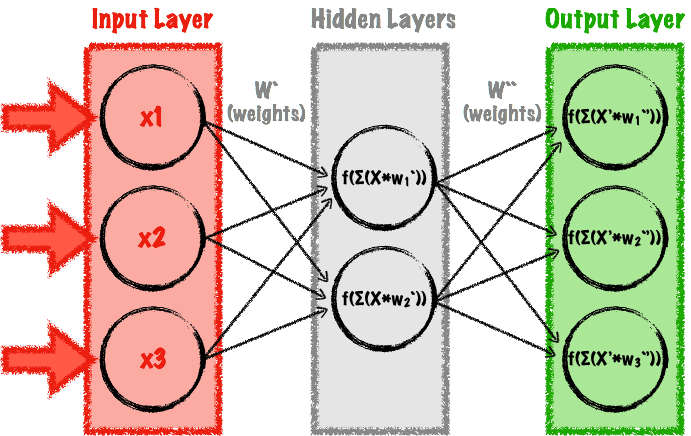
图4.简单的前馈自编码机,通过MLP实现。图片由Mateusz Dymczyk提供
MLP的主要优点是它们很容易建模,训练速度快。 而且,研究人员基于MLP展开了大量研究,可以认为它们的工作机制已经被较好的理解了。
在进行MLP建模时,作为模型的创建者,您需要弄清楚几件事情,其中包括:
•隐藏层的数量和每层神经元的数量
•每个神经元中使用的激活函数的类型
•用于训练的优化器
所有这些选择都会影响你模型的结果。 如果您选择了错误的参数,那么您的网络可能根本不会收敛,需要很长时间才能收敛(例如,如果您选择的是不好的优化器或错误的学习率),在真实数据上过拟合或者欠拟合。
我们来看看代码中最重要的部分。
数据准备
我们首先使用Pandas DataFrame从我们的CSV文件中读取数据。 这将返回一个Pandas的DataFrame:
train_data_raw = pd.read_csv(‘resources/normal.csv’)
validate_data_raw = pd.read_csv(‘resources/verify.csv’)
现在我们要提取列,我们将实际用于训练和预测:
feature_list = [” LinAccX (g)”]
features = len(feature_list)
train_data_selected = train_data_raw[feature_list].as_matrix()
validate_data_selected = validate_data_raw[feature_list].as_matrix()
在我们开始建模网络之前,我们需要做更多的预处理。 MLP网络的主要缺点是缺乏“记忆”。在训练和预测期间,每个记录被视为一个单独的个体样本。 然而,在处理时间序列时,观测样本之间的依赖性是非常重要的。 我们的数据中的一个尖峰并不一定意味着一个异常:这取决于它的环境。
为了解决这个问题,我们将使用一个简单的方法创建窗口记录 ,这个方法将通过记录进行记录,并追加window – 1记录(在我们的例子中, 窗口大小将被设置为25,但是这个值应该基于您的使用案例,您读入数据的频率,以及您希望模型预测异常的速度,可能会牺牲准确性)。 这种新型的记录将具有window * features大小,并将在时间步长之间模拟时间依赖性。 如果我们想利用第一个window – 1读进来的样本,我们需要将它们填充到合适的长度,因为MLP网络需要一个定长的输入。 在这个例子中,我们将用零填充它们:
def prepare_dataset(dataset, window):
windowed_data = []
for i in range(len(dataset)):
start = i + 1 – window if i + 1 – window >= 0 else 0
observation = dataset[start : i + 1,]
to_pad = (window – i – 1 if i + 1 – window < 0 else 0) * features
observation = observation.flatten()
observation = np.lib.pad(observation, (to_pad, 0), ‘constant’, constant_values=(0, 0))
windowed_data.append(observation)
return np.array(windowed_data)
在构建机器学习模型时,您不希望将所有数据用于训练 – 这可能会使您的模型过拟合。 出于这个原因,将数据分解为训练集和验证集是正常的,并且在训练期间使用两者来进行评估。 通常情况下,分割数据很容易,但是对于时间序列数据来说,它会变得更加复杂一些。 这是因为记录之间的时间依赖性:每个数据点出现的上下文是非常重要的。 这就是为什么在本教程中,我们不是随机抽样数据,而是简单地找到一个分割点,并将其用于将数据分成两个子集(80%的数据用于训练,20%用于测试):
rows = len(data_train)
split_factor = 0.8
train = data_train[0:int(rows*split_factor)]
test = data_train[int(rows*split_factor):]
现在我们需要准备一个DataLoader对象,它将以批处理的方式将数据提供给MXNet:
batch_size = 256
train_data = mx.gluon.data.DataLoader(train, batch_size, shuffle=False)
test_data = mx.gluon.data.DataLoader(test, batch_size, shuffle=False)
这个迭代器将以256个样本大小的Batch传递训练数据。 如果您在GPU上运行,那么这一点尤其重要,因为Batch过大可能会导致内存不足错误。 另一方面,太小的Batch会延长训练时间。
建模
由于使用Apache Gluon(MXNet的高级接口),建模代码非常简短。
我们的模型将是一系列用来代表隐藏层的块。 为了使建模变得容易,我们将使用gluon.nn.Sequential:
model = gluon.nn.Sequential()
with model.name_scope():
现在添加隐藏层,激活函数和压缩层是一个简单的MXNet方法调用:
model.add(gluon.nn.Dense(16, activation=’tanh’)) # Adds a fully connected layer with 16 neurons and a tanh activation
model.add(gluon.nn.Dropout(0.25)) # Adds a dropout layer
这会将输入传递给包含16个神经元的第一个隐层,然后将其传递给激活层(在本例中为“tanh”),这不仅比其他许多激活方法在计算上更节约,而且看上去能够快速收敛,让训练出的MLP网络有更高精度。因为剔除了部分数据,因此不会过度拟合。 在我们的网络中,我们将Dropout层的输出传递给另一个隐层,并且再次重复这个循环(隐藏层有8个和16个神经元 – 隐藏层应该有比输入层更少的层来寻找结构)。 我们的最后一层将不会有任何激活或dropout,它将被视为输出层。
在建模之前,我们需要为网络参数(在这种情况下,我们使用所谓的Xavier初始化,分配初始值,并准备一个训练器对象(在这里我们使用的是Adam优化器 ):
model.collect_params().initialize(mx.init.Xavier(), ctx=ctx)
trainer = gluon.Trainer(model.collect_params(), ‘adam’, {‘learning_rate’: 0.001})
对于这个问题(我们有兴趣计算输出层和输入层之间形成的损失函数),我们可以使用gluon.loss.L2Loss来计算均方误差:
L = gluon.loss.L2Loss()
最后,我们准备一个评估方法,它将检查我们的模型在每个Epoch之后的效果如何:
def evaluate_accuracy(data_iterator, model, L):
loss_avg = 0.
for i, data in enumerate(data_iterator):
data = data.as_in_context(ctx) # Pass data to the CPU or GPU
label = data
output = model(data) # Run batch through our network
loss = L(output, label) # Calculate the loss
loss_avg = loss_avg*i/(i+1) + nd.mean(loss).asscalar()/(i+1)
return loss_avg
并循环训练多个Epoch:
epochs = 50
all_train_mse = []
all_test_mse = []
# Gluon training loop
for e in range(epochs):
for i, data in enumerate(train_data):
data = data.as_in_context(ctx)
label = data
with autograd.record():
output = model(data) #Feed the data into our model
loss = L(output, label) #Compute the loss
loss.backward() #Adjust parameters
trainer.step(batch_size)
train_mse = evaluate_accuracy(train_data, model, L)
test_mse = evaluate_accuracy(test_data, model, L)
all_train_mse.append(train_mse)
all_test_mse.append(test_mse)
图5显示了模型对于我们的训练数据和验证数据有多接近。
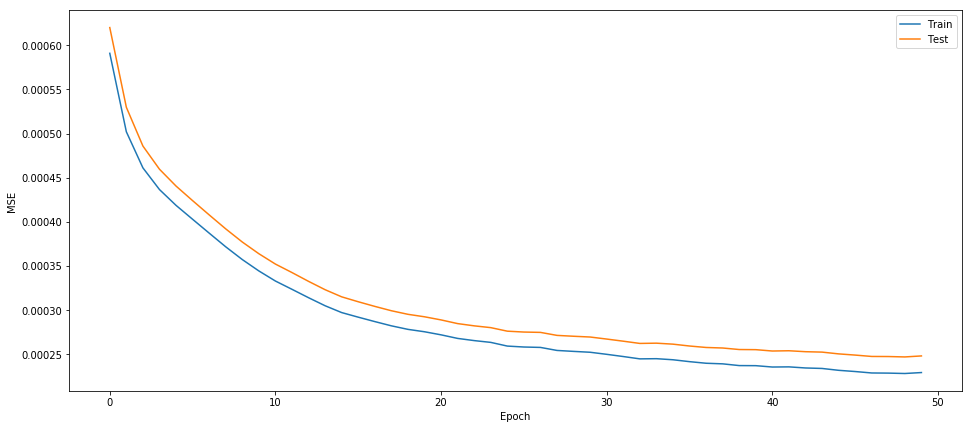
图5.训练和验证数据的MSE结果 图片由Mateusz Dymczyk提供
拟合模型后,我们可以提供新的数据做出预测:
def predict(to_predict, L):
predictions = []
for i, data in enumerate(to_predict):
input = data.as_in_context(ctx)
out = model(input)
prediction = L(out, input).asnumpy().flatten()
predictions = np.append(predictions, prediction)
return predictions
在计算所有训练数据的MSE后,我们可以设定异常的阈值:
threshold = np.mean(errors) + 3*np.std(errors)
最后,我们可以对一个测试数据集进行预测,在这种情况下,通过对机器人引擎进行编程来模拟系统宕机(另一种选择是使用统计方法来生成错误的数据)。 图6显示了最终的红色异常。
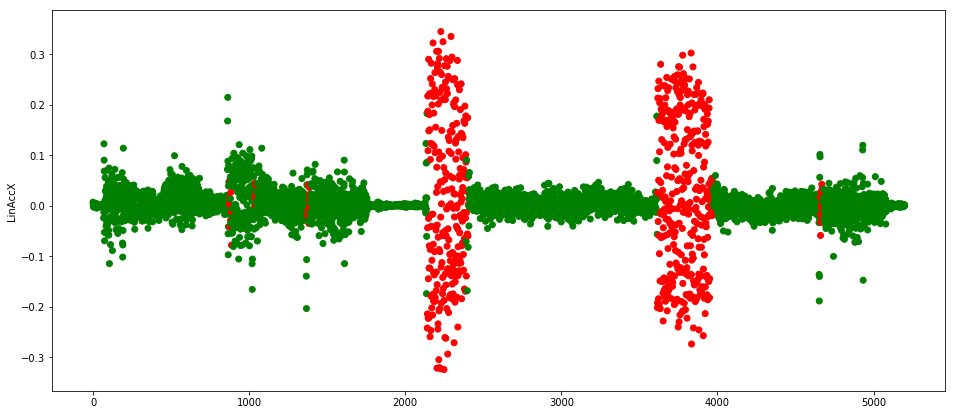
图6.测试数据集中的异常值。图片由Mateusz Dymczyk提供
由于程序的设定,机器人会在2000个周期左右以及4000个周期前面一点都会停止,MLP在这里的诊断是正确的。
而且我们能看到,尽管训练数据集包含了0.1到0.2之间的散点,但是神经网络足够聪明,可以发现如果有多个这样的读数连在一起,那么很可能是出错了。 我们也注意到,它正确地预见到了在1000个周期左右,具有这样的值的读数并非是异常的,当然模型错误地汇报了一些异常。我们可能需要调整一些参数(使用Dropout,正则化或数据分割方法)以获得更好的模型。
对数据集进行窗口化的必要性,可以通过使用窗口大小为1的参数运行脚本来进行比较(见图7):
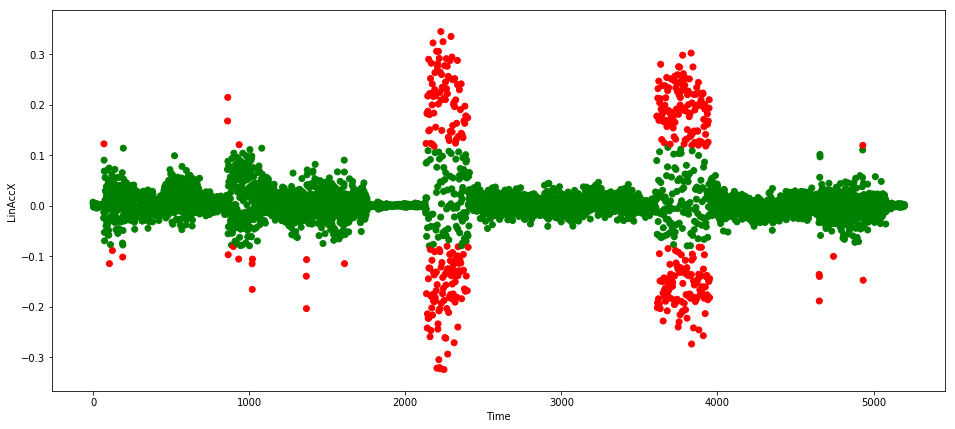
图7.不恰当的窗口大小下,训练的MLP结果。图片由Mateusz Dymczyk提供
我们清楚地看到,网络不考虑任何时间结构,只是简单地过拟合了大部分训练数据集,大约在[-1,1]之间。 该范围之外的所有散点都被错误地标记为异常。
LSTM
现在我们已经有了一个可行的基本解决方案,让我们再考虑一下我们的问题。 在MLP例子的“数据准备”一节中,我们提到,使用MLP网络训练,样本不会保留以前的任何信息,这可能存在问题。 这是因为,在时间序列分析中,时间依赖往往是非常重要的。 MLP例子中,我们的开窗策略是克服这个缺点的一种很粗糙的方法。
为了克服这个缺点,我们现在来看看循环神经网络(RNN)。 在FF网络(前馈神经网络)中,它们将使用具有激活函数的神经元来构建,但主要的区别是它们也将包含循环。 我们不仅要把样本点馈送到网络,而且还要把网络的之前的隐含状态也要馈送进来。图8显示了RNN的架构。
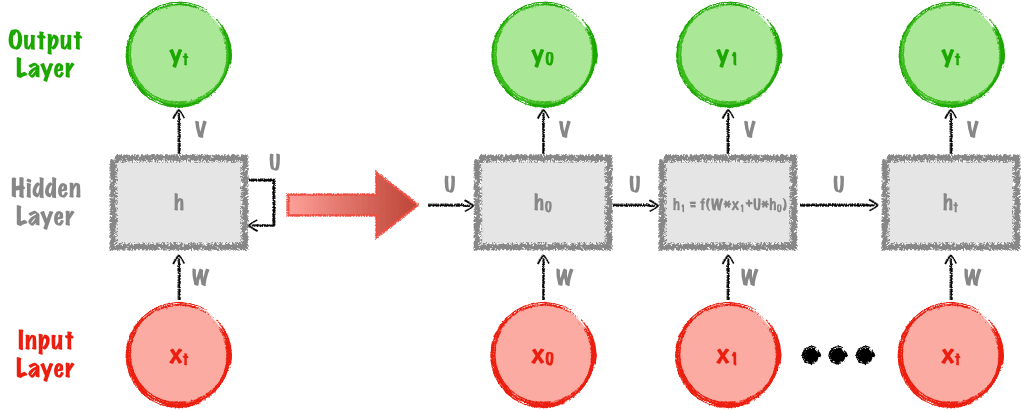
图8.递归神经网络。 图片由Mateusz Dymczyk提供
传统RNNs的主要问题是,当使用例如tanh或类似的输出总是在[-1,1]范围内的激活层时,它们将大量的信息编码成小的输出范围。 这使得学习长期依赖非常具有挑战性。 例如,当建立一个预测句子中下一个单词的模型时,如果下一个单词能使用前几个单词推理出来,那么我们可能会做的很好。 但是另一方面,如果要求联系更远的上下文(几个句子以外),我们可能无法保留足够的“长期”信息来做出适当的预测。
这个数学问题,是由于一个叫做梯度消失和梯度爆炸现象。 在后一种情况下,我们网络中的权重可能开始呈指数级增长,可能变得比他们应该取的值更大。 这个问题可以通过简单的截断或挤压太高的值来解决。 前者(梯度消失)问题更大,其中一些(或全部)权重按指数规模变小,有时会变得很小,以至于计算机上的舍入错误可能使整个模型完全失效。
这些问题导致了所谓的长期短期记忆网络 (LSTM)的建立。 LSTM背后的基本思想是,它们像传统的RNN一样,具有链式结构,保留以前的信息,但速度更为稳定。 而普通 RNNs在每个单元格内只有一个激活层,LSTM使用输入门(决定什么新的信息应该传递到网络),遗忘门(决定以怎样的速率遗忘什么信息),和输出门计算新状态,如图9所示。
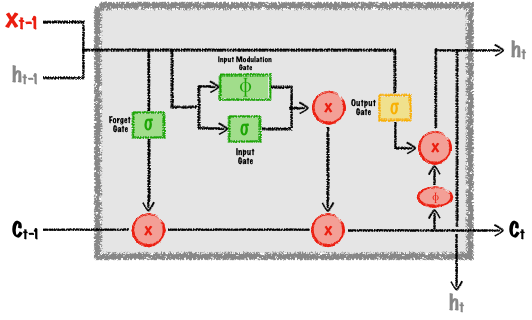
图9. LSTM网络中的Cell。图片由Mateusz Dymczyk提供
通过将输出的数量设置为与输入数量相同的值,我们可以再次获得一个自编码机 – 这是一个自己记住以前状态的自编码机。
与我们的MLP例子相比,我们不会做任何预先的数据预处理。 不过,我们将把数据再次分割成训练集和验证集。 Gluon为我们提供了一些不太一样的数据加载器抽象类:
split_factor = 0.8
train = train_data_selected.astype(np.float32)[0:int(rows*split_factor)]
validation = train_data_selected.astype(np.float32)[int(rows*split_factor):]
train_data = mx.gluon.data.DataLoader(train, batch_size, shuffle=False)
validation_data = mx.gluon.data.DataLoader(validation, batch_size, shuffle=False)
封装类可以很容易地对LSTM甚至更复杂的深层LSTM序列进行建模。下面的代码创建一系列堆叠的神经网络块,使用Xavier初始化初始化所有参数,生成一个优化器,并准备一个损失函数:
model = mx.gluon.nn.Sequential()
with model.name_scope():
model.add(mx.gluon.rnn.LSTM(window, dropout=0.35))
model.add(mx.gluon.rnn.LSTM(features))
# Use the non default Xavier parameter initializer
model.collect_params().initialize(mx.init.Xavier(), ctx=ctx)
# Use Adam optimizer for training
trainer = gluon.Trainer(model.collect_params(), ‘adam’, {‘learning_rate’: 0.01})
# Similarly to previous example we will use L2 loss for evaluation
L = gluon.loss.L2Loss()
在Gluon中的训练是在一个简单的for循环中进行的,循环了变量epochs指定的次数:
e range ( epochs ):
for i , enumerate data ( train_data ):
data = data . as_in_context ( ctx ) . reshape (( – 1 , features , 1 ))
label = data
with autograd . record ():
output = model ( data )
loss = L ( output , label )
loss . backward ()
trainer . step ( batch_size )
对于每个Epoch,这个代码将使用我们的训练数据逐批地使用model(data)调用计算输出,然后计算损失并使用训练器对象更新所有参数。 MSE结果如图10所示。

图10.第一个LSTM模型如何拟合训练和验证数据。 图片由Mateusz Dymczyk提供
在这种情况下,两个MSE值同时快速收敛到0.这可能意味着我们的模型正在过拟合,并应该调整网络设计的某些部分。
使用与我们之前的例子相同的技术,我们可以获得一个阈值,并在我们的测试集上运行预测,产生如图11所示的结果。
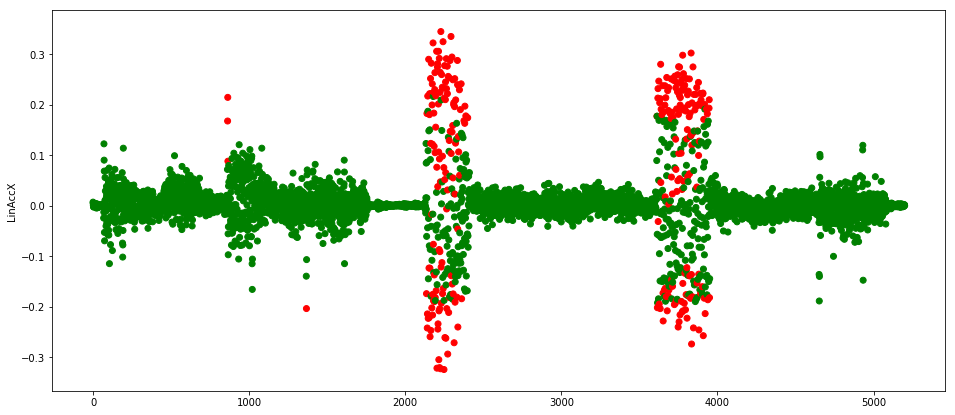
图11. LSTM的结果。图片由Mateusz Dymczyk提供
我们这次可以看到,网络并不总是把错误读数汇报为异常,但是足以让我们检测到机器的问题了。
进一步改进
尽管我们能够在本教程中创建看似实用的模型,但仍然有几个重要方面我们没有时间来讨论:
1.数据准备。针对您的数据集,您可能需要了解其他数据准备步骤。例如,将神经网络的时间序列数据标准化通常是一个好主意。在其他情况下,您将需要对您的特征进行编码,比如那些分类变量。
2.网络架构优化。不同的用例需要不同数量的隐藏层,激活函数,正则化函数,优化器,DropOut层等。
3.如果再次阅读LSTM Gluon 文档和LSTM计算图,您会注意到LSTM问题中,每个样本都可以定义为一系列观测。同样,如在MLP的例子中,我们可以使用我们的窗口方法,使每个观察包含几个观测样本,并将其输入我们的LSTM网络。在这种情况下,网络可能会更多地利用读取之间的时间依赖性,而网络的输入仍然只有特征的数量大小发生变化。
4.不同的训练/验证分离策略和自动模型评估。我们只通过绘制和检查样本测试集来评估我们的模型。在现实世界中,您需要准备打过标签的测试数据集(例如使用统计量数据),并使用某种度量标准(例如预测和回测)以自动化的方式查看模型的执行情况。
结论
在本教程中,我们解决了时间序列物联网数据中的异常检测问题。 正如我们现在所看到的,异常检测是一个非常广泛的问题,不同的用例需要不同的技术来进行数据准备和建模。 我们探索了两种稳健的方法:前馈神经网络和长期的短期记忆网络,各有优缺点。 FFN的速度更快(在NVidia 1080 GPU上,执行50个Epoch为5.5秒,25个Epoch为33秒),但是需要更多规划和准备,而LSTM则稍微慢一些,但也更加智能。 深层神经网络被证明是非常善于发现结构和依赖的,但是相应的代价是,我们至少需要了解如何构建它们的基本知识。 最后,我们看到诸如Apache MXNet之类的框架,使得这个高难度任务变得平易近人起来。
这篇文章由O’Reilly和亚马逊合作完成。 在此处查看我们的编辑独立性声明。





