使用Kafka和Pulsar的一个常见用例是创建任务队列。这两种技术为实现此用例提供了不同的实现。我将讨论用Kafka和Pulsar实现任务队列的方法,以及每个任务队列各自的相对优势。
什么是任务队列?
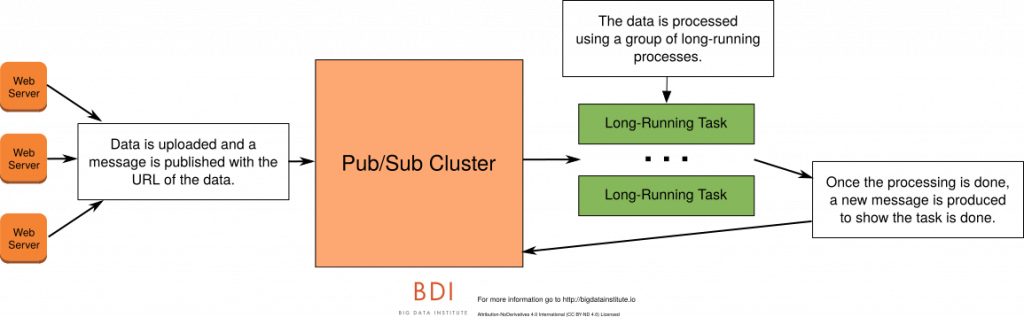
任务队列正在使用消息传递技术通过发布消息来添加工作单位。此消息将由另一个进程(最好是一组进程)使用,然后对其进行某种处理。
任务队列与其他处理的时间量不同。大多数常规处理(如ETL或简单处理)的数据应用毫秒度量,最长不超过1秒。任务队列将处理更长的时间,以秒、分钟、小时度量。
这也称为分布式任务队列。这是因为单个机器或流程不足以满足需求。我们必须在许多不同的进程和计算机上分发处理流程。随着对分布式技术的这种需求,任务的复杂性增加了10-15倍。
任务队列的例子
为了帮助您理解任务队列,让我举几个我在现实世界中看到的简单例子。所有例子的共同点是需要长时间处理,并尽快返回结果。
视频转码
某些用例要求用户上传视频。此视频将保存到存储桶中。上传视频后,Web服务将发布将由消费者群集使用的消息。该消息将包含要转码的视频的存储区URL。这些消费者集群进程将对视频进行转码或预处理成网络友好的格式准备播放。转码需要几分钟到几小时才能完成。视频完成后,转码过程应发布视频已准备好的消息。
语音识别与情感分析
在一些例子中,处理呼叫中心的电话呼叫数据需要被处理。呼叫完成后,需要进行多个处理流程。首先,呼叫的语音对话需要进行语音识别才能将音频更改为文本。接下来,文本将对其进行各种NLP或情绪分析。整个处理过程需要1-60分钟。处理完成后,需要发布一条消息来标记对话、或对对话进行打分。
任务队列有什么困难?
最开始碰到的困难是任务负载平衡。您需要确保一个有一个长时间运行的进程不备份队列的其余部分。其余的任务需要继续有增无减。您还需要能够随着流量上下浮动自动扩展群集。
任务队列的难点问题是容错:
- 你怎么知道一个进程是否挂掉,如果挂掉了,你如何知道它何时挂掉?
- 你如何重启任务处理?
- 进程死亡时,你如何检测?
这些问题的答案是针对特定技术的。当您处理任务队列时,这些问题的答案对您的技术选择至关重要。
为什么不批处理?
一个常见的问题是为什么要使用实时系统而不是批处理系统?批处理系统将具有固有的周转时间。对于30秒的处理时间,您可以花费5-10秒等待分布式系统分配和启动资源。实时任务队列的关键之一是结果的速度。批处理系统处理此数据的效率太低。
使用卡夫卡的任务队列
现在你了解了任务队列以及与它们相关的难点,让我们专门用Apache Kafka创建任务队列。
高水位和任务队列
在了解如何在Kafka中创建任务队列之前,您需要了解Kafka消费者如何标记他们已经消费了消息。卡夫卡消费者通过提交偏移量来执行此任务。 Kafka消费者进程使用commitSync或commitAsync方法。这些方法使用关于主题、数据分区的Map函数,用偏移量(offset)作为参数。
卡夫卡消费者使用所谓的高水位来记录消费。这意味着消费者只能说,“我已经处理到了这一点”,而不是“我已经处理完了这个消息。” 这是卡夫卡和其他工具的一个重要区别。 Kafka没有内置的方式确认单个消息是否处理。
消费者偏移量使用的这种高水位方法,意味着无法找到单个的错误。例如,如果消费者正在处理来自同一分区的两个任务,而其中一个失败了,那么Kafka缺乏内置的能力来说哪一个失败了,哪一个成功了。卡夫卡客户端可以说我已经处理到了这一点,而无关工作成功与否。
要解决这种局限性,你需要将每个分区视为它自己的工作“线程”。每个分区将限制为一次处理一件事。当消费者完成这项工作时,它会调用commitSync将处理标记为已完成(提高水位)。
由于您要在分区中保持长时间运行的工作,因此您必须创建更多分区来有效地处理数据。虽然您可能已经开始使用20-30个分区,但您可能会使用100个分区。这个分区的数量是为Kafka准备的,因此消费者组将有足够的分区来有效地分配负载。
不言而喻的是,您需要根据您将要做的工作量来扩大您的消费者集群。
管理自己的提交
你会注意到我多次使用“内置”这个词。这是因为还有另一种选择不是Kafka内置的。你必须编写所有这些代码,处理方式是你自定义的。
如您所见,Kafka消费者的问题是他们的高水位限制。您可以通过编程方式开始处理消费者的偏移量。最简单的方法是使用数据库。你会关闭Kafka的自动偏移提交。你可以在数据库而不是Kafka中进行偏移的更新插入操作。这些更新插入将基于每个主题、分区、偏移量以及当前状态来完成。
当消费者进程重新启动时,消费者需要知道其分区是如何指派的。它会进行数据库查找以查找最后一个偏移量及其状态。如果最后一个偏移量有错误,消费者进程将开始处理该消息。
虽然这会增加更多的编程开销,但这是我与团队合作时推荐的方法。
Pulsar的任务队列
既然您已经了解了如何使用Kafka创建任务队列,那么让我们看看它和Apache Pulsar比较起来是怎样的。
Pulsar中的选择性确认(Selective Acking,SACK)
我们之前了解过卡夫卡的高水位特性。 Pulsar支持这种类型的确认,另一种类型称为选择性确认。选择性确认允许消费者仅确认单个消息。您可以在此了解有关选择性确认的更多信息。
当谈到任务队列时,选择性确认确实改变了游戏规则。通过任务队列,我们能够确认我们已经处理了该消息。为此,我们将使用acknowledgement方法。
要获取失败的消息,可以调用redeliverUnacknowledgedMessages(重新投递未确认消息)方法。这将使Pulsar重新获得所有未经确认的消息。另一个名为ackTimeout(确认超时)的设置将自动重新发送超过超时阈值的所有消息。
任务队列有另一个好处,我以前没有谈过。即使有许多不同的分区,一些分区仍然可能是热点,或接收大量的任务。 Pulsar使用共享订阅更好地解决了这个问题。共享订阅允许跨消费者进行循环分发。这样可以比Kafka更均匀地分配工作。
对于Pulsar中的任务队列,您将发布消息。此消息将由许多不同的消费者进程中的一个上的共享订阅使用。消费者将开始实际处理数据。一旦完成该处理,消费者将选择性地确认该消息。它会产生一条消息,表明处理已经完成。
注意:Pulsar旨在将任务队列作为它的一种特定用例。它在雅虎是用于此目的的。这是我们看到它们差异如此巨大的重要原因。
创建分布式任务队列
您选择的消息传递技术确实会改变您实现分布式任务队列的方式。虽然可以使用任一解决方案创建任务队列,但Kafka和Pulsar有不同的创建方法。使用Pulsar创建分布式任务队列要容易得多。
如果您有任务队列用例,请确保正确使用工具。这些用例很难自己编码去处理实际操作时与它们相关的问题。

Jesse Anderson
Jesse Anderson是Big Data Institute(大数据学院)的数据工程师,创意工程师和常务董事。 Jesse为员工提供大数据培训,培训内容包括Apache Kafka,Apache Hadoop和Apache Spark等尖端技术。 他教过成千上万的学生,这些学生遍布从初创到财富100强的各种公司,从他这里获得了数据工程师的技能。 他被广泛认为是该领域的专家,并因其新颖的教学实践而受到广泛认可。 Jesse受到O’Reilly及Pragmatic Programmers的宣传,并且吸引了类似Wall Street Journal, CNN, BBC, NPR, Engadget, and Wired这种主流媒体的报道。你可以在Jesse-Anderson.com 了解关于他的更多信息。





