在过去多年里机器学习(ML)走过了很长的路。它从纯学术领域的一个实验性研究课题,发展成为真实世界里的问题的一个自动化解决方案,从而在很多行业里被广泛应用。但是很多时候,这些算法还是被看成是“炼金术”,因为对于这些模型的内部运作机制的理解还很欠缺(可以查看Ali Rahimi在2017年NIPS上的论文)。通常为了能确定算法进行的预测决定是可靠的,需要能验证这些机器学习系统的推理过程。研究人员和从业人员正在纠结于预测模型可能带来的人类无法预期的结果的伦理道德问题,例如那些用来评估是否能获得住房贷款的算法,或是无人驾驶汽车的算法(可以查看Kate Crawford在2017年NIPS会议上的论文《The Trouble with Bias》)。数据科学家Cathy O’Neil最近写了一整本书,其中充满了可解释性差的例子作为警告,希望引起那些对不恰当模型可能会带来的潜在的社会冲突的重视。这些模型的例子有在刑事判决中模型的偏见或在构建财务模型时使用带有人为偏见的虚拟特征。
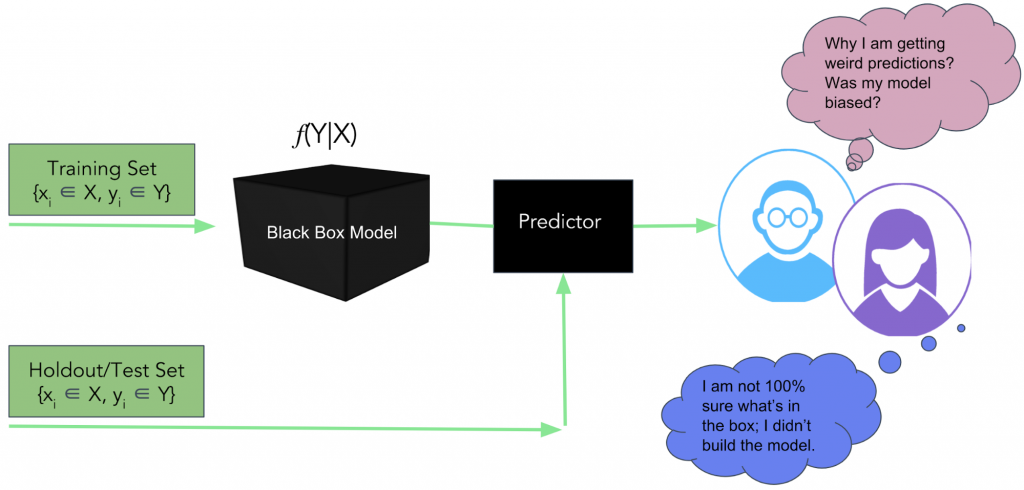
图1 传统的解释预测模型的方法还不够好。图片由Pramit Choudhary提供
平衡模型的可解释性和模型的性能需要进行一定的取舍。从业人员通常会用线性模型而不是更复杂的模型,通过降低性能来提升可解释性。这在不少对于错误的预测代价没那么高的业务场景里可能没什么。但是,在某些场景里(比如信用得分或司法系统里)模型必须既很准确还可理解。事实上,能解释预测模型的公平性和透明性的能力已经在法律规范上被强制了。
在我作为首席数据科学家的DataScience.com,我们有着强烈的意愿去赋能从业人员使用模型来确保安全、无歧视和透明。我们看到了大家(对模型)可解释性的需求,并在最近开源了一个Python框架,叫Skater。把它作为给数据科学领域的研究人员和从业人员赋能模型可解释性的第一步。
模型的评估是一个复杂的问题,因此我会分两篇来讨论它。在第一篇里,我会从把模型可解释性作为一个理论概念来深入探讨,并对Skater做了一个高层的概述。在第二篇里,我会给出一个关于Skater目前支持的模型的更详细的解释,以及Skater的发展路线图。
什么是模型可解释性?
模型可解释性这个概念在机器学习领域还是一个很新的概念,非常主观,而且不少时候也是有争议的(可以看这里Yann LeCun针对Ali Rahimi的观点的回应)。模型可解释性是指能解释和验证预测性模型所做出的决策的能力,从而保证算法的决策过程是公平、负责任和透明的。Adrian Weller的《Challenges of Transparency》一文里有对于机器学习里的透明性的定义更详细的解释。更正式的说法是,模型可解释性可以被定义为能更好地理解机器学习的响应函数如何解释自变量(输入)和因变量(目标)之间的关系的能力(最好是以人类可理解的方式)。
理想情况下,你应该能查看模型,从而理解算法决策了什么?为什么?以及如何做出的决策。
- 模型能提供什么信息来避免预测错误?你应该能查看并理解隐性变量间的关系,从而能及时评估和理解什么特征是预测的主要因素。这将能确保模型的公平性。
- 为什么模型用特定的方式运作?你应该能够识别和验证产生模型输出的相关变量。这样做能让你信任预测系统的可靠性,即便是在无法预见的场景里。这种分析能确保模型的可靠性和安全性。
- 我们如何能信任模型做出的预测?你应该能向利益相关方和同行证明,给出任意输入的数据,模型都能按预期的方式运作。这就能保证模型的透明性。
现有能获取模型可解释性的技术
模型可解释性是指能对数学模型有更好的理解,大部分情况下是通过更好地理解对模型做出主要贡献的特征来获得的。这种形式的解释是有可能通过使用流行的数据探索和可视化方法(例如,层次化聚类和维度降低技术)来获得。而更进一步的模型评估和验证则可以使用模型比较算法,利用分类和回归模型特定的指标进行。这些指标包括AUC-ROC(ROC曲线下面积)和MAE(平均绝对误差)。下面让我们快速查看几种技术。
探索性数据分析和可视化
探索性数据分析能对数据产生更好的理解,相应地也能为构建更好的预测性模型提供专业意见。在模型构建的过程中,获得模型可解释性可能意味着探索数据集,从而能可视化和理解“有意义的”数据内部结构,并以人能理解的方式提取出信号强度高的特征。这对于无监督学习问题可能更有益处。下面让我们看看几个常用的可以用于模型可解释性的数据探索技术。
- 聚类:层次化聚类
- 降维技术:主成分分析(见图2)
- 变分自编码(VAE):使用变分自编码技术的一种自动生成型方法
- 流形学习(Manifold Learning):t-分布邻域嵌入算法(t-SNE,见图3)
在本文里,我们会关注监督学习问题相关的模型解释。
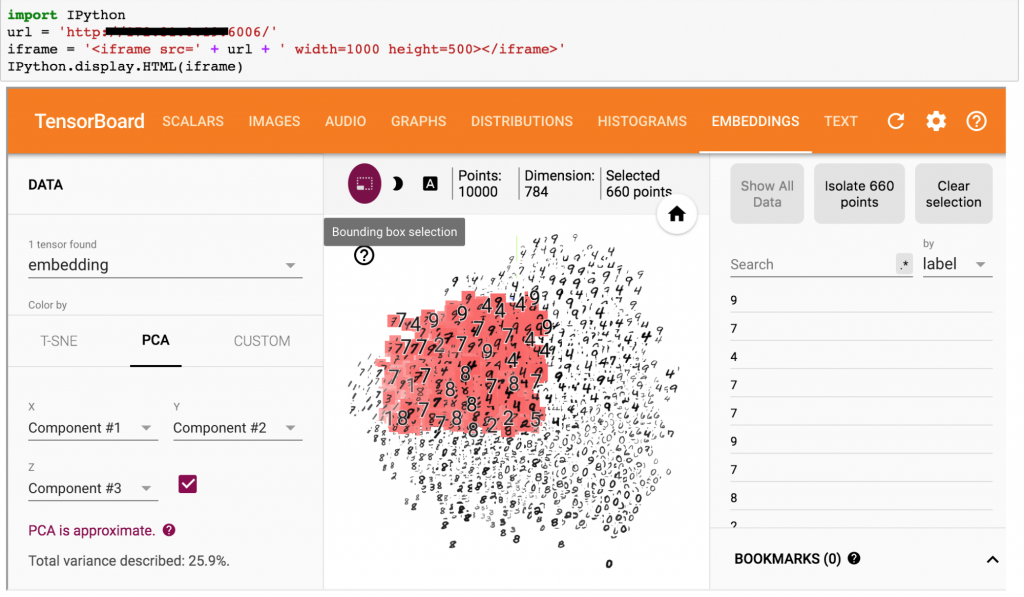
图2 使用TensorFlow和PCA对高维MNIST数据进行3D可视化的解释,从而构建领域知识。图片由Pramit Choudhary和Datascience.com团队友情提供
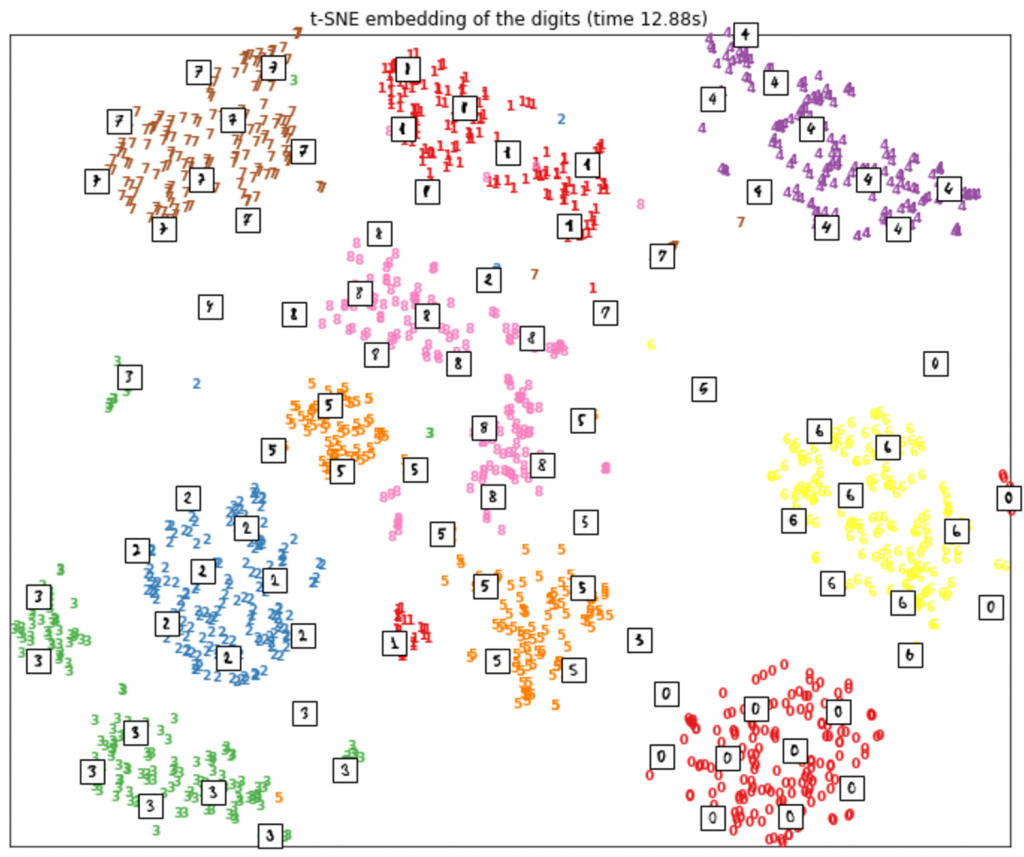
图3 使用sklearn里的t-SNE功能可视化MNIST数据。图片由Pramit Choudhary和Datascience.com团队友情提供
B.模型的比较和性能评估
除了数据探索技术,一个极度简单的模型可解释性的形式可能是使用模型评估技术。分析师和数据科学家可以使用模型比较和评估方法来评估模型的准确度。例如,使用分类和回归的交叉验证方法和评估指标,你可以测量一个预测模型的性能。你可以优化模型的超参数来平衡偏差和方差(看这篇《Understanding the Bias-Variance Tradeoff》)。
- 分类:例如F1-得分,AUC-ROC,brier分数等。图3显示了AUC-ROC是如何在一个多分类的问题里帮助测量模型对于流行的鸢尾花数据集的表现。ROC的AUC是一个广为流行的指标,它能帮助平衡真正率和假正率。它对处理类别不平衡问题也很鲁棒。如图3所示,ROC AUC(类别2)值为86%说明训练的分类器给予一个正样本(属于类别2)比负样本(不属于类别2)可能性要高的概率是86%。这种聚合后的表现指标可能对仔细说明一个模型的整体表现更有帮助。然而,它还是无法在出现误分类错误时给出更详细的信息。例如,为什么一个本属于类别0的样本被分配到类别2,而一个属于类别2的样本被划分到类别1?要记住的是,每一个误分类的例子可能都有着不一样的潜在的业务影响。
- 回归:例如,r-平方分数(决定系数),均方误差等。
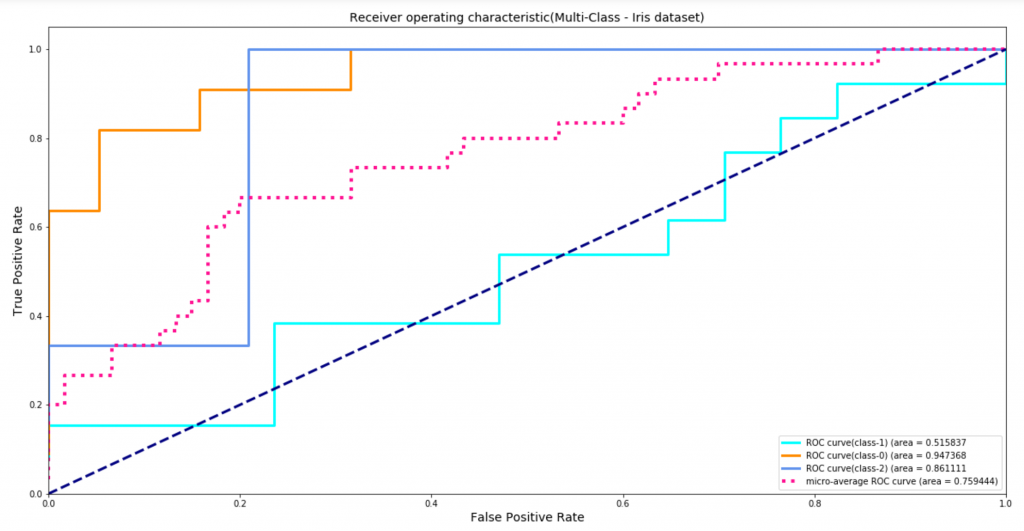
图4 通过ROC曲线下面积来测量模型在鸢尾花数据集(用sklearn处理一个多分类问题)的表现。图片由Pramit Choudhary和Datascience.com团队友情提供
为什么想要更好的模型可解释性?
如果这个预测模型的目标函数(即损失函数试图去优化的)与业务指标(和你现实世界目标紧密关联的)相一致,而且用于训练的数据集是比较稳定的,上述的数据探索方法和使用评估技术计算的评估分数可能对于评测模型在一个样本数据集上的整体表现是足够的。然而,在现实世界的场景里这种情况是非常少见的,因此使用分数估计来获得模型的表现是不够的。例如,网络安全领域的一个入侵检测系统(IDS)容易发生规避攻击,攻击者可能会使用对抗性输入来击败安全系统。注:对抗性输入是一种攻击者有意地欺骗机器学习算法来让它们做出错误的预测的例子。在这个场景里,模型的目标函数就不是真实世界目标的一个好的表示。这就可能需要一个更好的模型解释来发现算法里的盲点,以便通过混合训练数据来规避对抗攻击,从而构建一个安全和保险的模型。想了解更多,可以看看Moosavi-Dezfooli等2016的论文《DeepFool》以及Goodfellow等2015年的论文《Explaining and harnessing adversarial examples》。
另外,模型在一个静态数据集(不考虑新数据带来的变化)上训练的表现会随着时间逐渐平稳下来。例如,在模型被部署应用后或者新的信息被加入训练数据后,现有的特征空间可能会发生改变,带来新的未知的关联,同时也意味着简单地再次对模型进行训练对于提高模型预测能力是不够的。更好的可解释性就很有必要,从而能有效地调整模型来理解算法的行为,或是依据数据里的新关联和交互而调整算法。
还可能有另外一种场景,其中模型的预测是对的,也是按照期望的方式进行的预测。但是由于数据的偏差性,它在道义上无法证明其在社会场景的决策是正确的。例如,仅仅因为我喜欢黑泽明并不意味着我想看《3 Ninjas》。此时,可能需要对算法的内部工作机制进行更严格和透明的审查,才能构建更有效的模型。
即使有人不同意上述所有作为激励提升可解释性的原因,传统的模型评估形式也需要一个关于统计检验的算法或属性的合理的理论理解。非专家可能很难掌握有关算法的这些详细信息,这通常会导致数据驱动的计划失败。对于模型决策策略的人类可以理解的解释(HII,Human Interpretable Interpretation)可以作为在同行(分析师、管理人员、数据科学家和数据工程师)之间共享的富有洞察力的信息。
使用基于输入和输出这种形式的解释可能有助于促进更好的沟通和协作,使企业能够做出更自信的决策(例如,金融机构的风险评估/审计的分析)。重申一下,我们将模型可解释性定义为能解释一个预测模型的公平性(无偏差/无歧视)、可靠性(可靠的结果)和透明性(能够查看和验证预测的结果),而且目前这里的模型是针对于监督学习的问题。
性能和可解释性的平衡
在模型的性能和算法可解释性之间可能存在基本的权衡。机器学习从业人员经常倾向于更容易解释的模型——简单的线性模型、逻辑概率回归或决策树等,因为这些模型更容易被验证和解释。如果人们能理解模型内在工作机制或模型的决策策略,他们就能信任它。但是,当试图去把这些预测模型部署到真实世界来解决问题时,它们要处理高维异类的复杂数据集,实现自动化的信用卡申请、欺诈检测或预测一个客户的生命周期价值,这时可解释的模型的表现通常会不好。当从业人员试图去用更复杂的算法来改进模型的表现(例如准确度)时,他们又要努力去权衡模型的性能和可解释性。
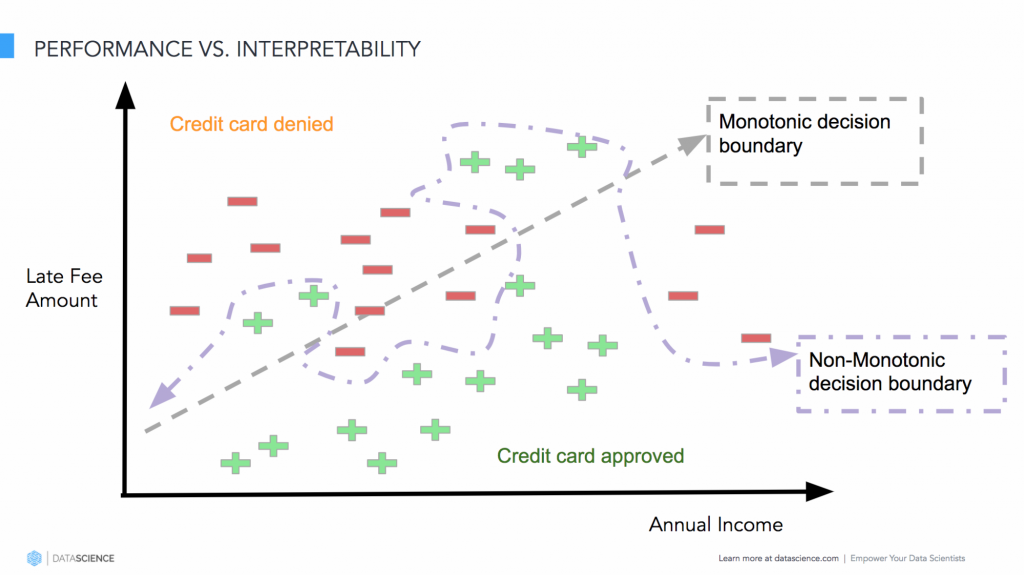
图5 模型的性能和可解释性的对立。图片由Pramit Choudhary和Datascience.com团队友情提供
让我们用一个例子再看看平衡性能和可解释性的问题。如图5所示,假定要构建一个模型,针对一群用户来预测是否要批准贷款。类似于使用对数损失函数或最小二乘函数的逻辑概率回归这样的线性模型更容易被解释,因为输入变量和模型的输出的联系可以使用模型的系数权重在幅度和方向上被量化。如果决策边界是单调增加或减少的,这种思路就可以正常工作。但是,实际数据很少会出现这种情况。因此,在模型的性能和可解释性之间取得平衡就存在窘境。
为了能获得自变量和模型的响应函数之间的非单调的关系,通常就不得不使用更复杂的模型:集成模型、带有大量决策树的随机森林或是带有多层隐藏层的神经网络。而且伴随着文本数据(参见《Explaining Predictions of Non-Linear Classifiers in NLP using layer-wise relevance propagation (LRP)》)、计算机视觉(Ning等在NIPS 2017的论文《Relating Input Concepts to Convolutional Neural Network Decisions》)和基于语音等需要人类解释的模型的引入,问题的复杂度进一步增加。例如,理解与语言相关的模型依然是一个难题,因为类似的词语所带来的模糊性和不确定性。引入可解释性来理解语言模型中的这种模糊性对于构建业务场景特定的规则来理解、验证和改进模型的决策是非常有用。
Skater简介
在Datascience.com,我们自己也在多个分析场景和项目里经历过可解释性的挑战,深刻理解对于更好的模型可解释性的需求。这里的模型可解释性更多的是指关于输入变量和模型输出的人类可解释的解释(HII),这个解释要对非专家都容易理解。我特别记得一个项目。当时我们要构建一个机器学习的模型来总结消费者的评价。我们希望获取消费者的情感(正面还是负面的),以及每个情感的具体原因。由于时间比较紧,我们认为使用一个开箱即用的情感分析模型可能是有价值的。我们看了很多市面上的选择,但是因为信任的问题没法决定要用哪个。我们觉得需要有更好的方法来解释、证明和验证这些模型。
在搜索过程中,我们没法找到一个成熟的开源库能一致地带来全局(对于一个全部的数据集)和局部(对于单个预测)的解释。因此我们从零开始开发了一个库,叫Skater(见图6)。
Skater是一个Python的库。专门被设计用来解密任何预测模型的内部工作机制。而且它是编程语言和框架无关的。目前,它提供算法来实现监督学习问题的可解释性。
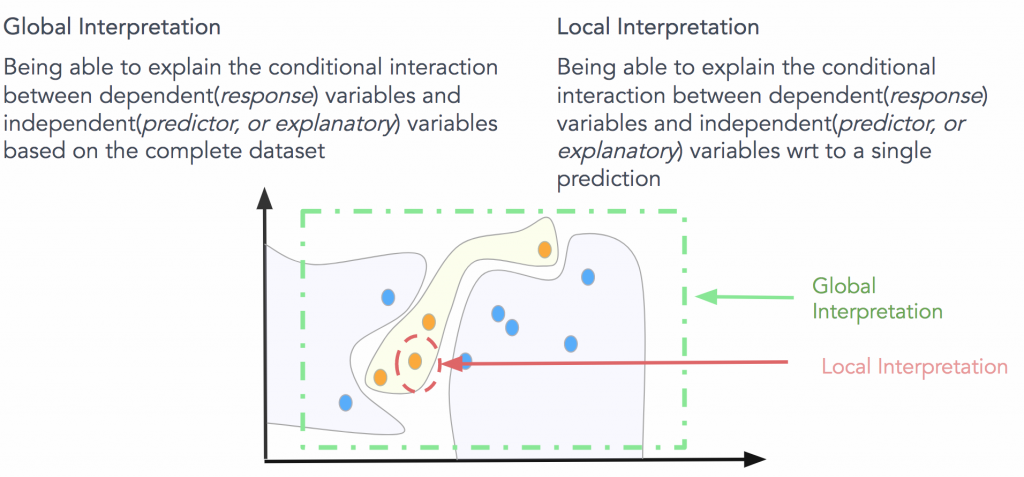
图6 总结全局和局部解释。图片由Pramit Choudhary和Datascience.com团队友情提供
目前支持的算法解释性在本质上是后验的。基于自变量(输入)和因变量(目标),Skater通过提供后验的机制来评估和证明预测模型的内在工作机制,因此它不支持构建可解释的模型(例如,规则集成、Friedman的论文和贝叶斯规则等)。
这一方法可以帮助我们依据分析业务场景来对机器学习模型产生可解释性,因为后验动作可能是很昂贵的,而且全面的可解释性也不是所有时候都需要的。Skater库结合了面向对象和函数式编程的范式,这对于提供可扩展性和高并发是必要的,同时还考虑到了代码的简洁性。这种可以解释的系统的一个总体的概览如图7所示。
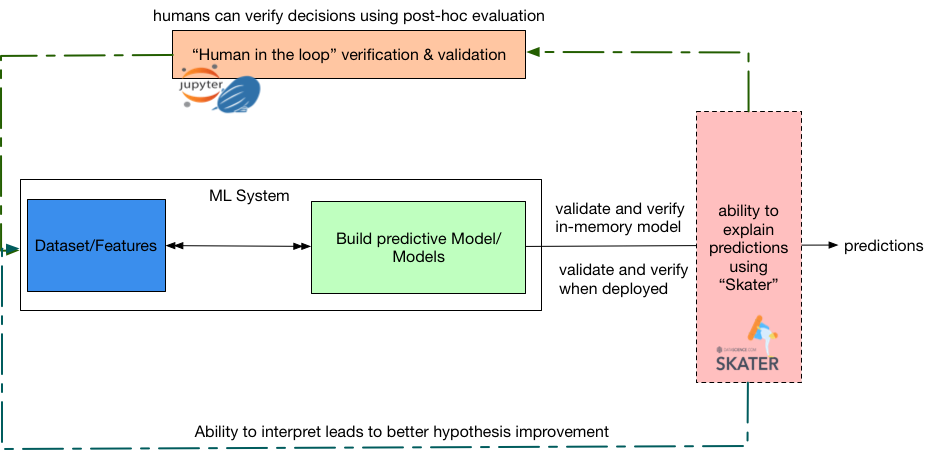
图7 使用Skater构建的一个可解释的机器学习系统。它能让人来优化常见的错误,从而带来更好和更有信心的预测。图片由Pramit Choudhary和Datascience.com团队友情提供
使用Skater实现模型可解释性
注:下面内嵌的样例代码的完整版在图名附带的超链接里。
使用Skater,我们可以:
- 对一个模型在完整数据集或单个样例所做预测的行为进行评估:通过利用和改进现有技术的组合,Skate可以获得全局以及局部的模型可解释性。对于全局性的解释,Skater目前使用模型无关的变量重要性方式以及部分依赖绘图来判断一个模型的偏差,并理解模型的一般行为。为了验证模型对于单个预测的判定策略,这个库使用了一个全新的技术,叫局部可理解的与模型无关的解释(LIME)。这个技术使用了一个局部代理模型来评估性能(这里可以找到关于LIME的更多信息)。其他的一些算法也在开发中。
from skater.core.explanations import Interpretation
from skater.model import InMemoryModel
…
eclf = VotingClassifier(estimators=[(‘lr’, clf1), (‘rf’, clf2), (‘gnb’, clf3)], voting=’soft’)
…
models = {‘lr’:clf1,
‘rf’:clf2,
‘gnb’:clf3,
‘ensemble’:eclf}
interpreter = Interpretation(X_test, feature_names=data.feature_names)
Global interpretation with model agnostic feature importance
for model_key in models:
pyint_model = InMemoryModel(models[model_key].predict_proba, examples=X_test)
ax = ax_dict[model_key]
interpreter.feature_importance.plot_feature_importance(pyint_model,
ascending=False, ax=ax)
ax.set_title(model_key)
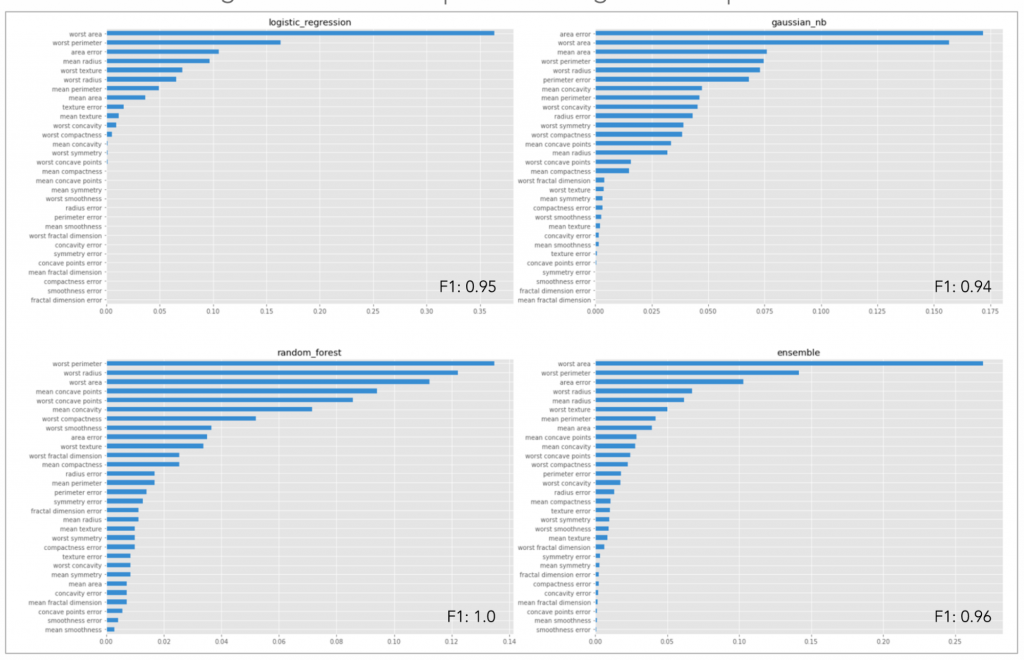
图8 使用Skater对不同类型的监督学习预测模型进行模型比较。这里,模型无关的特征重要性被用来比较有着差不多F1值的模型。可以看出不同类型的模型基于它们对预测器的假设、因变量和相关性的理解,对特征产生的排序是不同的。这种形式的比较让机器学习领域的专家和非专家都能一致地评估所选择的特征的相关性。图片由Pramit Choudhary和Datascience.com团队友情提供
- 发现隐性变量间的关系,并构建领域知识:从业人员可以使用Skater来发现隐性特征间的关系。例如,发现一个信用风险模型是如何使用银行客户的信用历史、支票账户状态以及现有的信用额度来批准或拒绝信用卡的申请,然后再把这些信息用于未来的分析。
# Global Interpretation with model agnostic partial dependence plot
def understanding_interaction():
pyint_model = InMemoryModel(eclf.predict_proba, examples=X_test,
target_names=data.target_names)
# [‘worst area’, ‘mean perimeter’] –> list(feature_selection.value)
interpreter.partial_dependence.plot_partial_dependence(list(feature_selection.value),
Pyint_model, grid_resolution=grid_resolution.value,
with_variance=True)
# Lets understand interaction using 2-way interaction using the same covariates
# feature_selection.value –> (‘worst area’, ‘mean perimeter’)
axes_list =
interpreter.partial_dependence.plot_partial_dependence([feature_selection.value],
Pyint_model, grid_resolution=grid_resolution.value,
with_variance=True)
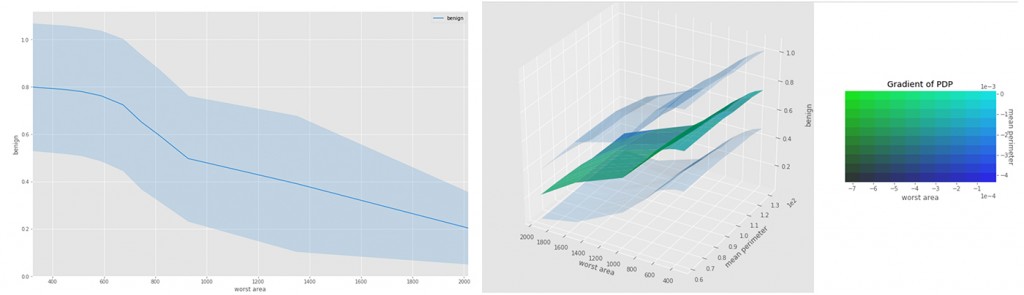
图9 在一个乳腺癌数据集上运用单向和双向交互来发现隐性特征间的关系。图片由Pramit Choudhary和Datascience.com团队友情提供
# Model agnostic local interpretation using LIME
from skater.core.local_interpretation.lime.lime_tabular import LimeTabularExplainer
…
exp = LimeTabularExplainer(X_train,
feature_names=data.feature_names,
discretize_continuous=False,
class_names=[‘p(No Cancer)’, ‘p(Cancer)’])
exp.explain_instance(X_train[52], models[‘ensemble’].predict_proba).show_in_notebook()
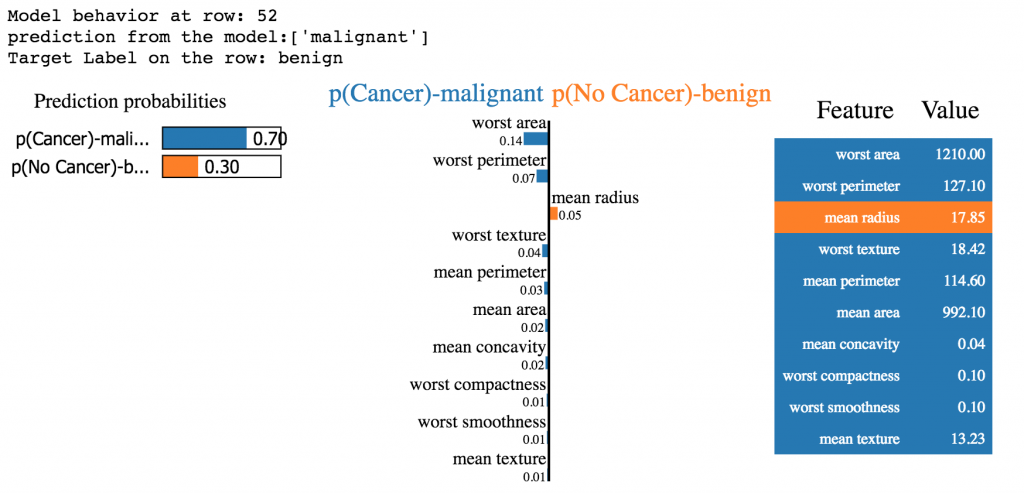
图10 通过LIME的线性代理模型来理解单个预测的特征相关性。图片由Pramit Choudhary和Datascience.com团队友情提供
- 在部署模型到生产环境后测量一个模型的性能是如何变化:无论训练测试还是已经部署到生产系统的模型,Skater都能带来一致的解释预测模型的能力。这就给了从业人员测量不同模型版本间特征关系是如何改变的机会(见图11)。当使用直接从机器学习市场(例如,algorithmia)里购买的开箱即用的模型时,这种形式的解释对于建立信心也是有用处的。例如,图12和13里是使用Skater对作用于IMDB的《纸牌屋》的评价数据的来自indico.io和algorithmia的开箱即用的情感分析模型进行比较和评估。两个模型都预测了一个正面的情感(1是正面,0是负面)。然而,indico.io的模型使用了一些本应该被忽略的停止词,例如”is”、 “that”和”of”。因此,尽管indico.io的模型相比来自algorithmia的模型返回了更高概率的正面情感,我们还是应该选择使用后者。
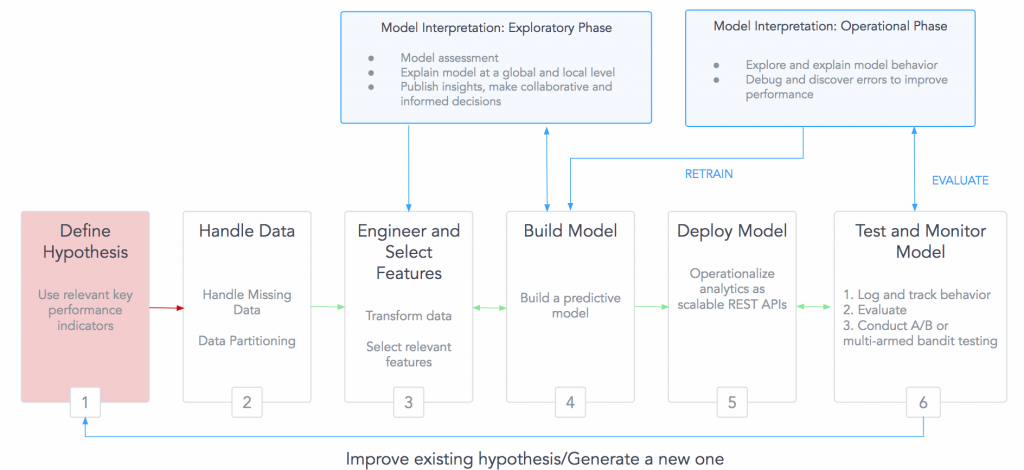
图11 强调了无论训练测试阶段(模型没有被应用)和部署之后(已经被应用)的模型的解释是很有必要的。对特征的更好的解释可能带来更好的特征工程和特征选择。图片由Pramit Choudhary和Datascience.com团队友情提供
# Using Skater to verify third-party ML marketplace models
from skater.model import DeployedModel
from skater.core.local_interpretation.lime.lime_text import LimeTextExplainer
…
#an example document
test_documents = [“Today its extremely cold, but I like it”]
#the API address
algorithmia_uri = “https://api.algorithmia.com/v1/algo/nlp/SentimentAnalysis/1.0.3”
…
dep_model = DeployedModel(algorithmia_uri,
algorithmia_input_formatter,
algorithmia_output_formatter,
request_kwargs=kwargs)
…
l = LimeTextExplainer()
print(“Explain the prediction, for the document:\n”)
print(test_documents[0])
l.explain_instance(test_documents[0]
, dep_model
, num_samples=500).show_in_notebook()
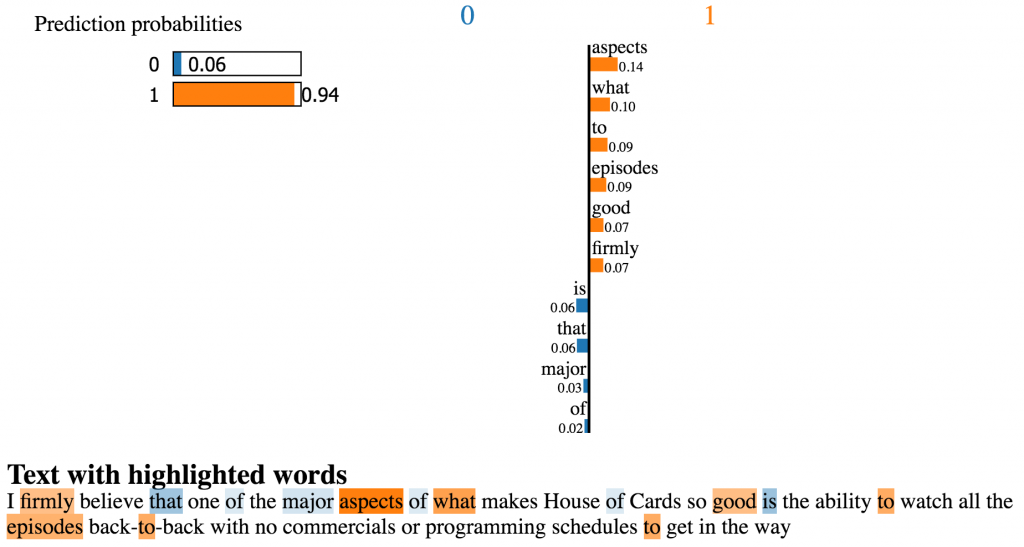
图12 对开箱即用的模型(预训练部署的模型,来自indico.io)应用可解释性。图片由Pramit Choudhary和Datascience.com团队友情提供

图13对开箱即用的模型(预训练部署的模型,来自algorithmia)应用可解释性。图片由Pramit Choudhary和Datascience.com团队友情提供
结论
在当今的预测性模型生态系统里,能解读和验证算法决策策略从而能提供透明性的方法将会扮演一个重要的角色。能够获得对模型可解读的解释可能会带来对于更多复杂算法的使用,特别是在那些对法规有要求的行业里。随着Skater的初步发布,我们正在向着在机器学习领域面向专家和非专家来提供预测模型的决策策略的公正性、可靠性和透明性的方向跨出了一步。如果你想了解更多的现实世界里运用Skater的模型可解释性能力的案例,可以看一看这本书《Practical Machine Learning with Python》。
在本系列的第二篇里,我们将会进一步的探索理解Skater目前支持的模型,以及Skater未来的发展路线。
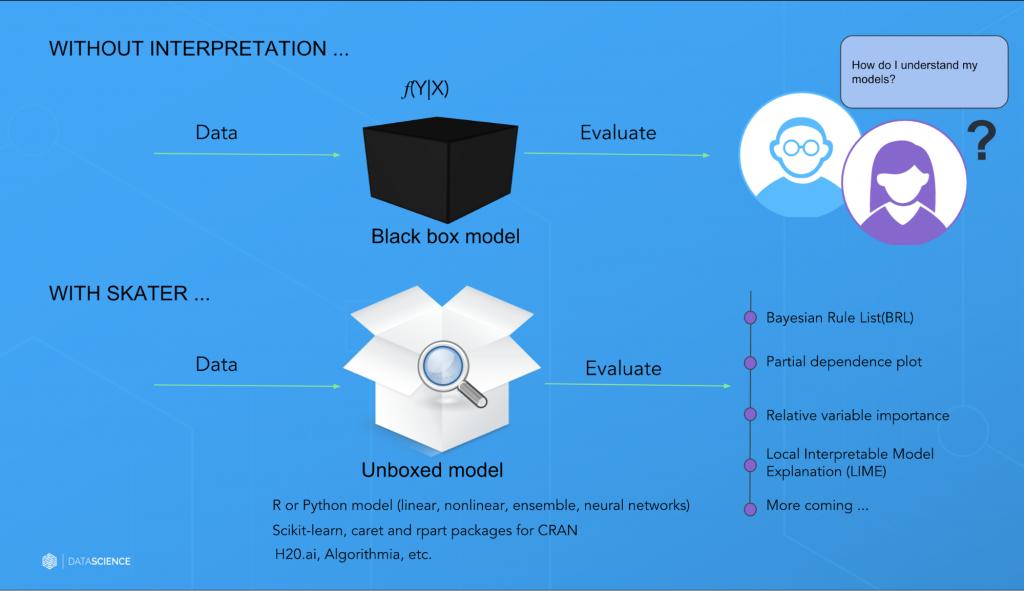
图14 Skater的综述。图片由Pramit Choudhary和Datascience.com团队友情提供
想了解更多信息,请查看这些资源和工具、案例以及gitter频道。
致谢
我要非常感谢Aaron Kramer、Brittany Swanson、Colin Schmidt、Dave Goodsmith、Dipanjan Sarkar、Jean-René Gauthie、Paco Nathan、Ruslana Dalinina以及匿名审稿人在本文完成过程中的帮助。
参考资料和进一步的阅读内容:
- Zachary C. Lipton的 2016年论文《The Mythos of Model Interpretability》
- Marco Tulio Ribeiro、Sameer Singh和Carlos Guestrin的2016年论文《 Nothing Else Matters: Model-Agnostic Explanations By Identifying Prediction Invariance》
- Finale Doshi-Velez和Been Kim的 2017年论文《Towards A Rigorous Science of Interpretable Machine Learning》
- 欧盟议会和理事会2016年制定的《General data protection regulation》
- 解释机器学习的一些想法
- 解释和解读深度神经网络
- John P. Cunningham等2016年论文《 Linear Dimensionality Reduction》
- Saleema Amershi 等2015年论文《 Model Tracker》
- Perter Norvig对于可解释的AI的一些思考
- Kate Crawford等2014年的报告《 Toward a Framework to Redress Predictive Privacy Harms》
- A. Weller在ICML 2017会议上的论文《Challenges for Transparency》
- 针对偏差来检查算法
- 《There is a blind spot in AI research》 ,Kate Crawford和Ryan Calo的文章
- PCA
- 如何有效地使用t-SNE
- Sebastian Raschka的2016年论文《Model Evaluation and Selection》

Pramit Choudhary
Pramit Choudhary是位于加利福尼亚州洛杉矶的DataScience.com的首席数据科学家。他的研究重点是优化和应用机器学习和贝叶斯设计策略以解决现实问题的有效方法。在DataScience.com,他正在领导各种方案,以找出方法来降低构建有效模型的混乱、评估模型以及缩小原型与生产中部署模型之间差距。加入DataScience.com前,他曾在初创公司和大企业工作,参与使用预测分析解决问题,从而提高石油和天然气行业、社交媒体分析、推荐引擎、匹配和欺诈检测等行业的生产力。总的来说,他是一个渴望解决具有挑战性问题的人。





