许多使用了TensorFlow的工作流,需要在图像或视频数据上用GPU来有效地训练模型。 然而,这些工作流同时也包含多个阶段的数去前后处理,这些处理工作可能不需要在GPU上运行。 如图1所示,这种混合处理阶段,导致数据科学团队在系统中不仅需要CPU,同时用『交流基本靠吼』的模式管理GPU资源,在办公室里喊:『嘿,有谁在占用GPU机器吗?』 我们急需一种统一的方法论,进行多阶段工作流调度,数据管理和把某部分模型载入到GPU上。
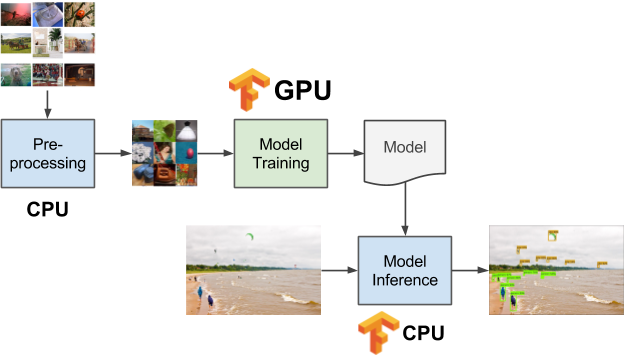
图1. 在机器学习的不同阶段使用CPU和GPU。 感谢Daniel Whitenack提供图片
将Kubernetes与TensorFlow配合使用,为这些类型的工作流程提供了一个非常优雅、易于管理的解决方案。例如,图1显示了三个不同的数据处理阶段。 数据预处理在CPU上运行,模型训练在GPU上发生,而模型推断再次在CPU上进行。 人们可能需要在一组共享的计算资源(例如,云服务实例上)上部署和维护每一个工作流阶段,这就是Kubernetes最擅长的。 每个阶段都可以通过Docker进行容器化,并用声明的形式,通过Kubernetes部署于一个机器集群上(见图2)。
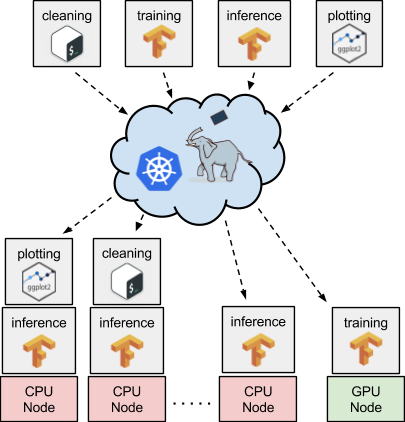
图2. 使用Kubernetes和Pachyderm在CPU或GPU上安排任务。 感谢Daniel Whitenack提供图片
除了调度和部署之外,您还可以利用Kubernetes生态系统中的其他开源工具(如Pachyderm)来确保在正确类型的节点(即CPU或GPU节点)上把正确的数据送入正确的TensorFlow代码。 Pachyderm充当Kubernetes顶层的容器化数据管线层。通过使用这个工具,您可以将TensorFlow处理的不同阶段订阅到特定版本的数据集(以对象存储数据库作为后端)上,并自动收集输出,这些输出又可以送给其他处理阶段作为输入,这些阶段可能运行在相同节点上,也可能运行在不同节点上。而且,将我们工作流程的某些阶段(如模型训练截断)发送到GPU的过程如此简单,只需要通过一个JSON参数传给Pachyderm说, 『我们有个计算阶段需要一个GPU』。然后,Pachyderm将与Kubernetes合作,在拥有GPU的实例上对这个计算阶段进行调度。
听起来不错对吗? 那么,你可以自己试试在Kubernetes上,按如下方法运行TensorFlow + GPU:
1.将Kubernetes部署到您选择的云/私有云中。某些云提供商(例如Google云平台,Google Cloud Platform)甚至会使用类似Google Kubernetes 引擎(GKE)等工具,一键部署Kubernetes。
2.将一个或多个GPU实例添加到您的Kubernetes集群。这可能涉及到一些操作,如果您正在使用GKE,您可能需要创建一个新的节点资源池,如果您正在使用kops,您可能需要创先一个新的实例组。无论如何,您需要更新群集,在这些GPU节点上安装GPU驱动。举个例子,您可以通过gcloud命令,将新的节点池添加到您的alpha GKE集群(在这里可以使用最新的GPU高级特性):
$ gcloud alpha container node-pools create gpu-pool –accelerator type=nvidia-tesla-k80,count=1 –machine-type <your-chosen-machine-type> –num-nodes 1 –zone us-east1-c –image-type UBUNTU –cluster <your-gke-cluster-name>
然后你可以利用ssh访问该群集,添加nvidia GPU驱动:
$ curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
$ sudo -s
$ dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
$ apt-get update && apt-get install cuda -y
1.在您的Kubernetes集群上部署Pachyderm来管理数据管线,以及您的输入/输出数据集。
2.将你的工作流程的不同阶段使用Docker进行容器化。
3.通过引用您的Docker镜像以及JSON参数,部署您的数据管线。如果您需要GPU,只需使用Kubernetes提供的资源请求和限制功能,即可获取。 请注意,您可能需要将GPU驱动程序的路径添加到容器中的LD_LIBRARY_PATH环境变量,详述见此处。
如果您还有任何问题,或需要更多信息:
• 查看有关使用Kubernetes调度GPU的文档。
• 检查Pachyderm文档 。
• 通过加入公众Pachyderm Slack和/或Kubernetes Slack获得帮助。
• 运行一个Tensorflow + Kubernetes示例。
这篇文章由O’Reilly和TensorFlow合作完成。在这里查看我们的编辑独立声明。

Daniel Whitenack
Daniel Whitenack拥有博士学位,是一位训练有素的数据科学家/工程师,具备为大中小型公司开发数据科学应用程序的工业经验,其中包括预测模型,数据面板,推荐引擎等等。 Daniel在世界各地的会议(Gopherfest,GopherCon 等)上发言。他为Jupyter维护Go内核,对于各种开源数据科学项目,他都进行了积极的帮助,并组织开发者贡献代码。





